Where do gravitational waves like GW170817 come from? Using our network of detectors, we cannot pinpoint a source, but we can make a good estimate—the amplitude of the signal tells us about the distance; the time delay between the signal arriving at different detectors, and relative amplitudes of the signal in different detectors tells us about the sky position (see the excellent video by Leo Singer below).
In this paper we look at full three-dimensional localization of gravitational-wave sources; we important a (rather cunning) technique from computer vision to construct a probability distribution for the source’s location, and then explore how well we could localise a set of simulated binary neutron stars. Knowing the source location enables lots of cool science. First, it aids direct follow-up observations with non-gravitational-wave observatories, searching for electromagnetic or neutrino counterparts. It’s especially helpful if you can cross-reference with galaxy catalogues, to find the most probable source locations (this technique was used to find the kilonova associated with GW170817). Even without finding a counterpart, knowing the most probable host galaxy helps us figure out how the source formed (have lots of stars been born recently, or are all the stars old?), and allows us measure the expansion of the Universe. Having a reliable technique to reconstruct source locations is useful!
This was a fun paper to write [bonus note]. I’m sure it will be valuable, both for showing how to perform this type of reconstruction of a multi-dimensional probability density, and for its implications for source localization and follow-up of gravitational-wave signals. I go into details of both below, first discussing our statistical model (this is a bit technical), then looking at our results for a set of binary neutron stars (which have implications for hunting for counterparts) .
Dirichlet process Gaussian mixture model
When we analyse gravitational-wave data to infer the source properties (location, masses, etc.), we map out parameter space with a set of samples: a list of points in the parameter space, with there being more around more probable locations and fewer in less probable locations. These samples encode everything about the probability distribution for the different parameters, we just need to extract it…
For our application, we want a nice smooth probability density. How do we convert a bunch of discrete samples to a smooth distribution? The simplest thing is to bin the samples. However, picking the right bin size is difficult, and becomes much harder in higher dimensions. Another popular option is to use kernel density estimation. This is better at ensuring smooth results, but you now have to worry about the size of your kernels.
Our approach is in essence to use a kernel density estimate, but to learn the size and position of the kernels (as well as the number) from the data as an extra layer of inference. The “Gaussian mixture model” part of the name refers to the kernels—we use several different Gaussians. The “Dirichlet process” part refers to how we assign their properties (their means and standard deviations). What I really like about this technique, as opposed to the usual rule-of-thumb approaches used for kernel density estimation, is that it is well justified from a theoretical point of view.
I hadn’t come across a Dirchlet process before. Section 2 of the paper is a walkthrough of how I built up an understanding of this mathematical object, and it contains lots of helpful references if you’d like to dig deeper.
In our application, you can think of the Dirichlet process as being a probability distribution for probability distributions. We want a probability distribution describing the source location. Given our samples, we infer what this looks like. We could put all the probability into one big Gaussian, or we could put it into lots of little Gaussians. The Gaussians could be wide or narrow or a mix. The Dirichlet distribution allows us to assign probabilities to each configuration of Gaussians; for example, if our samples are all in the northern hemisphere, we probably want Gaussians centred around there, rather than in the southern hemisphere.
With the resulting probability distribution for the source location, we can quickly evaluate it at a single point. This means we can rapidly produce a list of most probable source galaxies—extremely handy if you need to know where to point a telescope before a kilonova fades away (or someone else finds it).
Gravitational-wave localization
To verify our technique works, and develop an intuition for three-dimensional localizations, we used studied a set of simulated binary neutron star signals created for the First 2 Years trilogy of papers. This data set is well studied now, it illustrates performance it what we anticipated to be the first two observing runs of the advanced detectors, which turned out to be not too far from the truth. We have previously looked at three-dimensional localizations for these signals using a super rapid approximation.
The plots below show how well we could localise the sources of our binary neutron star sources. Specifically, the plots show the size of the volume which has a 90% probability of containing the source verses the signal-to-noise ratio (the loudness) of the signal. Typically, volumes are 

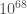
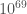
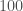
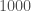

Localization volume as a function of signal-to-noise ratio. The top panel shows results for two-detector observations: the LIGO-Hanford and LIGO-Livingston (HL) network similar to in the first observing run, and the LIGO and Virgo (HLV) network similar to the second observing run. The bottom panel shows all observations for the HLV network including those with all three detectors which are colour coded by the fraction of the total signal-to-noise ratio from Virgo. In both panels, there are fiducial lines scaling inversely with the sixth power of the signal-to-noise ratio. Adapted from Fig. 4 of Del Pozzo et al. (2018).
Looking at the results in detail, we can learn a number of things
- The localization volume is roughly inversely proportional to the sixth power of the signal-to-noise ratio [bonus note]. Loud signals are localized much better than quieter ones!
- The localization dramatically improves when we have three-detector observations. The extra detector improves the sky localization, which reduces the localization volume.
- To get the benefit of the extra detector, the source needs to be close enough that all the detectors could get a decent amount of the signal-to-noise ratio. In our case, Virgo is the least sensitive, and we see the the best localizations are when it has a fair share of the signal-to-noise ratio.
- Considering the cases where we only have two detectors, localization volumes get bigger at a given signal-to-noise ration as the detectors get more sensitive. This is because we can detect sources at greater distances.
Putting all these bits together, I think in the future, when we have lots of detections, it would make most sense to prioritise following up the loudest signals. These are the best localised, and will also be the brightest since they are the closest, meaning there’s the greatest potential for actually finding a counterpart. As the sensitivity of the detectors improves, its only going to get more difficult to find a counterpart to a typical gravitational-wave signal, as sources will be further away and less well localized. However, having more sensitive detectors also means that we are more likely to have a really loud signal, which should be really well localized.

Left: Localization (yellow) with a network of two low-sensitivity detectors. The sky location is uncertain, but we know the source must be nearby. Right: Localization (green) with a network of three high-sensitivity detectors. We have good constraints on the source location, but it could now be at a much greater range of distances. Not to scale.
Using our localization volumes as a guide, you would only need to search one galaxy to find the true source in about 7% of cases with a three-detector network similar to at the end of our second observing run. Similarly, only ten would need to be searched in 23% of cases. It might be possible to get even better performance by considering which galaxies are most probable because they are the biggest or the most likely to produce merging binary neutron stars. This is definitely a good approach to follow.

Galaxies within the 90% credible volume of an example simulated source, colour coded by probability. The galaxies are from the GLADE Catalog; incompleteness in the plane of the Milky Way causes the missing wedge of galaxies. The true source location is marked by a cross [bonus note]. Part of Figure 5 of Del Pozzo et al. (2018).
arXiv: 1801.08009 [astro-ph.IM]
Journal: Monthly Notices of the Royal Astronomical Society; 479(1):601–614; 2018
Code: 3d_volume
Buzzword bingo: Interdisciplinary (we worked with computer scientist Tom Haines); machine learning (the inference involving our Dirichlet process Gaussian mixture model); multimessenger astronomy (as our results are useful for following up gravitational-wave signals in the search for counterparts)
Bonus notes
Writing
We started writing this paper back before the first observing run of Advanced LIGO. We had a pretty complete draft on Friday 11 September 2015. We just needed to gather together a few extra numbers and polish up the figures and we’d be done! At 10:50 am on Monday 14 September 2015, we made our first detection of gravitational waves. The paper was put on hold. The pace of discoveries over the coming years meant we never quite found enough time to get it together—I’ve rewritten the introduction a dozen times. It’s extremely satisfying to have it done. This is a shame, as it meant that this study came out much later than our other three-dimensional localization study. The delay has the advantage of justifying one of my favourite acknowledgement sections.
Sixth power
We find that the localization volume 
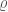




Typically, the uncertainty on a parameter (like the masses) scales inversely with the signal-to-noise ratio. This is the case for the logarithm of the distance, which means
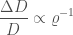
The uncertainty in the sky location (being two dimensional) scales inversely with the square of the signal-to-noise ration,
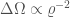
The signal-to-noise ratio itself is inversely proportional to the distance to the source (sources further way are quieter. Therefore, putting everything together gives
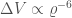
Treasure
We all know that treasure is marked by a cross. In the case of a binary neutron star merger, dense material ejected from the neutron stars will decay to heavy elements like gold and platinum, so there is definitely a lot of treasure at the source location.
 , we want to know the probability that the parameters
, we want to know the probability that the parameters 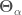 have different values, which is written as
have different values, which is written as  . This is calculated using
. This is calculated using ,
, is the likelihood, which we can calculate from our knowledge of the
is the likelihood, which we can calculate from our knowledge of the  is the prior on the parameters (what we would have guessed before we had the data), and the normalisation constant
is the prior on the parameters (what we would have guessed before we had the data), and the normalisation constant  is called the evidence. We’ll use the evidence again in the next layer of inference.
is called the evidence. We’ll use the evidence again in the next layer of inference. ,
,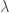 denotes which model we are considering.
denotes which model we are considering. , we can work this out using another application of Bayes’ theorem (yay)
, we can work this out using another application of Bayes’ theorem (yay) ,
, is just all the evidences for the individual events (given that model) multiplied together,
is just all the evidences for the individual events (given that model) multiplied together, 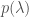 is our prior for the different models, and
is our prior for the different models, and 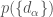 is another normalisation constant.
is another normalisation constant.



 , where
, where 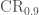 is the 90% sky area and
is the 90% sky area and 
 and
and 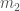 . The chirp mass is a combination these that we can measure really well, as it determines the most significant parts of the shape of the gravitational wave. It’s given by
. The chirp mass is a combination these that we can measure really well, as it determines the most significant parts of the shape of the gravitational wave. It’s given by .
.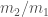 . We can get this from less dominant parts of the waveform, but it’s not typically measured as precisely as the chirp mass, so we’re often left with big uncertainties.
. We can get this from less dominant parts of the waveform, but it’s not typically measured as precisely as the chirp mass, so we’re often left with big uncertainties. to mean the probability of
to mean the probability of  . A joint probability describes the probability of two (or more things), so we have
. A joint probability describes the probability of two (or more things), so we have  as the probability that both
as the probability that both  happen. The probability that
happen. The probability that  . Consider the the joint probability of
. Consider the the joint probability of 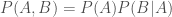 .
. .
. .
. ,
, . We normally have a model that can predict how likely it would be to observe that data if our hypothesis is true, so we know
. We normally have a model that can predict how likely it would be to observe that data if our hypothesis is true, so we know  , so we just need to convert between the two. This is known as the inverse problem.
, so we just need to convert between the two. This is known as the inverse problem. .
.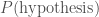 is the prior, because it’s what we believed about our hypothesis before we got the data, and
is the prior, because it’s what we believed about our hypothesis before we got the data, and  is the evidence. If ever you hear of someone doing something in a Bayesian way, it just means they are using the formula above. I think it’s rather silly to point this out, as it’s really the only logical way to do science, but people like to put “Bayesian” in the
is the evidence. If ever you hear of someone doing something in a Bayesian way, it just means they are using the formula above. I think it’s rather silly to point this out, as it’s really the only logical way to do science, but people like to put “Bayesian” in the  .
. . The prior probability of not having the disease is
. The prior probability of not having the disease is  . The likelihood of our positive result is
. The likelihood of our positive result is  , which seems worrying. The evidence, the total probability of testing positive
, which seems worrying. The evidence, the total probability of testing positive 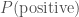 is found by adding the probability of a true positive and a false positive
is found by adding the probability of a true positive and a false positive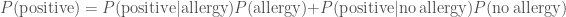 .
. . We thus have everything we need. Substituting everything in, gives
. We thus have everything we need. Substituting everything in, gives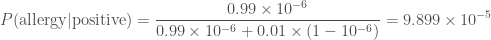 .
.
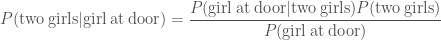 .
. . If we assume that it is equally likely that any one of the children opened the door, then the likelihood that one of the girls did so when their are two of them is
. If we assume that it is equally likely that any one of the children opened the door, then the likelihood that one of the girls did so when their are two of them is  . Similarly, if there were two boys, the probability of a girl answering the door is
. Similarly, if there were two boys, the probability of a girl answering the door is  . The evidence, the total probability of a girl being at the door is
. The evidence, the total probability of a girl being at the door is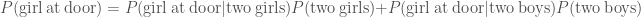 .
. .
. .
. , makes a difference. We know the probability of surviving the fatal dose is
, makes a difference. We know the probability of surviving the fatal dose is 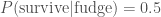 . The evidence, the total probability of surviving
. The evidence, the total probability of surviving  , is calculated by considering the two possible sequence of events: either Ted ate the fudge and survived or he didn’t eat the fudge and survived
, is calculated by considering the two possible sequence of events: either Ted ate the fudge and survived or he didn’t eat the fudge and survived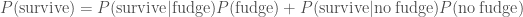 .
. . Since Ted either ate the fudge or he didn’t
. Since Ted either ate the fudge or he didn’t 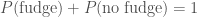 . Therefore,
. Therefore,![P(\mathrm{survive}) = 0.5 P(\mathrm{fudge}) + [1 - P(\mathrm{fudge})] = 1 - 0.5 P(\mathrm{fudge})](https://s0.wp.com/latex.php?latex=P%28%5Cmathrm%7Bsurvive%7D%29+%3D+0.5+P%28%5Cmathrm%7Bfudge%7D%29+%2B+%5B1+-+P%28%5Cmathrm%7Bfudge%7D%29%5D+%3D+1+-+0.5+P%28%5Cmathrm%7Bfudge%7D%29&bg=ffffff&fg=444444&s=0&c=20201002) .
. .
. . In this case,
. In this case, .
. . In this case we are in a state of ignorance. Our posterior is
. In this case we are in a state of ignorance. Our posterior is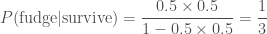 .
. .
. . Then
. Then .
.
