Probabilities are a way of quantifying your degree of belief. The more confident you are that something is true, the larger the probability assigned to it, with 1 used for absolute certainty and 0 used for complete impossibility. When you get new information that updates your knowledge, you should revise your probabilities. This is what we do all the time in science: we perform an experiment and use our results to update what we believe is true. In this post, I’ll explain how to update your probabilities, just as Sherlock Holmes updates his suspicions after uncovering new evidence.
Taking an umbrella
Imagine that you are a hard-working PhD student and you have been working late in your windowless office. Having finally finished analysing your data, you decide it’s about time to go home. You’ve been trapped inside so long that you no idea what the weather is like outside: should you take your umbrella with you? What is the probability that it is raining? This will depend upon where you are, what time of year it is, and so on. I did my PhD in Cambridge, which is one of the driest places in England, so I’d be confident that I wouldn’t need one. We’ll assume that you’re somewhere it doesn’t rain most of the time too, so at any random time you probably wouldn’t need an umbrella. Just as you are about to leave, your office-mate Iris comes in dripping wet. Do you reconsider taking that umbrella? We’re still not certain that it’s raining outside (it could have stopped, or Iris could’ve just been in a massive water-balloon fight), but it’s now more probable that it is raining. I’d take the umbrella. When we get outside, we can finally check the weather, and be pretty certain if it’s raining or not (maybe not entirely certain as, after plotting that many graphs, we could be hallucinating).
In this story we get two new pieces of information: that newly-arrived Iris is soaked, and what we experience when we get outside. Both of these cause us to update our probability that it is raining. What we learn doesn’t influence whether it is raining or not, just what we believe regarding if it is raining. Some people worry that probabilities should be some statement of absolute truth, and so because we changed our probability of it raining after seeing that our office-mate is wet, there should be some causal link between office-mates and the weather. We’re not saying that (you can’t control the weather by tipping a bucket of water over your office-mate), our probabilities just reflect what we believe. Hopefully you can imagine how your own belief that it is raining would change throughout the story, we’ll now discuss how to put this on a mathematical footing.
Bayes’ theorem
We’re going to venture into using some maths now, but it’s not too serious. You might like to skip to the example below if you prefer to see demonstrations first. I’ll use 




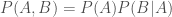
Alternatively, we could have

Both of our equations give the same result. (We’ve checked this before). If we put the two together then

Now we divide both sides by

this is Bayes’ theorem. I think the Reverend Bayes did rather well to get a theorem named after him for noting something that is true and then rearranging! We use Bayes’ theorem to update our probabilities.
Usually, when doing inference (when trying to learn from some evidence), we have some data (that our office-mate is damp) and we want to work out the probability of our hypothesis (that it’s raining). We want to calculate 

We can do this using Bayes’ theorem

In this context, we give names to each of the probabilities (to make things sound extra fancy): 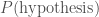

Whenever you get some new information, some new data, you should update your belief in your hypothesis using the above. The prior is what you believed about hypothesis before, and the posterior is what you believe after (you’ll use this posterior as your prior next time you learn something new). There are a couple of examples below, but before we get there I will take a moment to discuss priors.
About priors: what we already know
There have been many philosophical arguments about the use of priors in science. People worry that what you believe affects the results of science. Surely science should be above such things: it should be about truth, and should not be subjective! Sadly, this is not the case. Using Bayes’ theorem is the only logical thing to do. You can’t calculate a probability of what you believe after you get some data unless you know what you believed beforehand. If this makes you unhappy, just remember that when we changed our probability for it being raining outside, it didn’t change whether it was raining or not. If two different people use two different priors they can get two different results, but that’s OK, because they know different things, and so they should expect different things to happen.
To try to convince yourself that priors are necessary, consider the case that you are Sherlock Holmes (one of the modern versions), and you are trying to solve a bank robbery. There is a witness who saw the getaway, and they can remember what they saw with 99% accuracy (this gives the likelihood). If they say the getaway vehicle was a white transit van, do you believe them? What if they say it was a blue unicorn? In both cases the witness is the same, the likelihood is the same, but one is much more believable than the other. My prior that the getaway vehicle is a transit van is much greater than my prior for a blue unicorn: the latter can’t carry nearly as many bags of loot, and so is a silly choice.
If you find that changing your prior (to something else sensible) significantly changes your results, this just means that your data don’t tell you much. Imagine that you checked the weather forecast before leaving the office and it said “cloudy with 0–100% chance of precipitation”. You basically believe the same thing before and after. This really means that you need more (or better) data. I’ll talk about some good ways of calculating priors in the future.
Solving the inverse problem
Example 1: Doughnut allergy
We shall now attempt to use Bayes’ theorem to calculate some posterior probabilities. First, let’s consider a worrying situation. Imagine there is a rare genetic disease that makes you allergic to doughnuts. One in a million people have this disease, that only manifests later in life. You have tested positive. The test is 99% successful at detecting the disease if it is present, and returns a false positive (when you don’t have the disease) 1% of the time. How worried should you be? Let’s work out the probability of having the disease given that you tested positive

Our prior for having the disease is given by how common it is, 


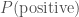
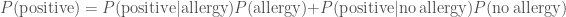
The probability of a false positive is 
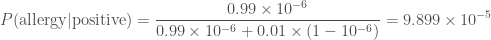
Even after testing positive, you still only have about a one in ten thousand chance of having the allergy. While it is more likely that you have the allergy than a random member of the public, it’s still overwhelmingly probable that you’ll be fine continuing to eat doughnuts. Hurray!

Doughnut love: probably fine.
Example 2: Boys, girls and water balloons
Second, imagine that Iris has three children. You know she has a boy and a girl, but you don’t know if she has two boys or two girls. You pop around for doughnuts one afternoon, and a girl opens the door. She is holding a large water balloon. What’s the probability that Iris has two girls? We want to calculate the posterior
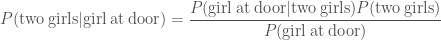
As a prior, we’d expect boys and girls to be equally common, so 


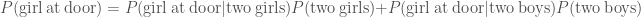
Using all of these,

Even though we already knew there was at least one girl, seeing a girl first makes it much more likely that the Iris has two daughters. Whether or not you end up soaked is a different question.
Example 3: Fudge!
Finally, we shall return to the case of Ted and his overconsumption of fudge. Ted claims to have eaten a lethal dose of fudge. Given that he is alive to tell the anecdote, what is the probability that he actually ate the fudge? Here, our data is that Ted is alive, and our hypothesis is that he did eat the fudge. We have

This is a case where our prior, the probability that he would eat a lethal dose of fudge 
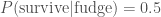

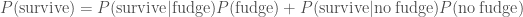
We’ll assume if he didn’t eat the fudge he is guaranteed to be alive, 
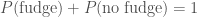
![P(\mathrm{survive}) = 0.5 P(\mathrm{fudge}) + [1 - P(\mathrm{fudge})] = 1 - 0.5 P(\mathrm{fudge})](https://s0.wp.com/latex.php?latex=P%28%5Cmathrm%7Bsurvive%7D%29+%3D+0.5+P%28%5Cmathrm%7Bfudge%7D%29+%2B+%5B1+-+P%28%5Cmathrm%7Bfudge%7D%29%5D+%3D+1+-+0.5+P%28%5Cmathrm%7Bfudge%7D%29&bg=ffffff&fg=444444&s=0&c=20201002)
This gives us a posterior

We just need to decide on a suitable prior.
If we believe Ted could never possibly lie, then he must have eaten that fudge and 

Since we started being absolutely sure, we end up being absolutely sure: nothing could have changed our mind! This is a poor prior: it is too strong, we are being closed-minded. If you are closed-minded you can never learn anything new.
If we don’t know who Ted is, what fudge is, or the ease of consuming a lethal dose, then we might assume an equal prior on eating the fudge and not eating the fudge, 
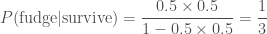
Even though we know nothing, we conclude that it’s more probable that the Ted did not eat the fudge. In fact, it’s twice as probable that he didn’t eat the fudge than he did as 
In reality, I think that it’s extremely improbable anyone could consume a lethal dose of fudge. I’m fairly certain that your body tries to protect you from such stupidity by expelling the fudge from your system before such a point. However, I will concede that it is not impossible. I want to assign a small probability to 

as the denominator is approximately one. Whatever small probability I pick, it is half as probable that Ted ate the fudge.

I would assign a much higher probability to Mr. Impossible being able to eat that much fudge than Ted.
While it might not be too satisfying that we can’t come up with incontrovertible proof that Ted didn’t eat the fudge, we might be able to shut him up by telling him that even someone who knows nothing would think his story is unlikely, and that we will need much stronger evidence before we can overcome our prior.
Homework example: Monty Hall
You now have all the tools necessary to tackle the Monty Hall problem, one of the most famous probability puzzles:
You are on a game show and are given the choice of three doors. Behind one is a car (a Lincoln Continental), but behind the others are goats (which you don’t want). You pick a door. The host, who knows what is behind the doors, opens another door to reveal goat. They then offer you the chance to switch doors. Should you stick with your current door or not? — Monty Hall problem
You should be able to work out the probability of winning the prize by switching and sticking. You can’t guarantee you win, but you can maximise your chances.
Summary
Whenever you encounter new evidence, you should revise how probable you think things are. This is true in science, where we perform experiments to test hypotheses; it is true when trying to solve a mystery using evidence, or trying to avoid getting a goat on a game show. Bayes’ theorem is used to update probabilities. Although Bayes’ theorem itself is quite simple, calculating likelihoods, priors and evidences for use in it can be difficult. I hope to return to all these topics in the future.
