The first observing run (O1) of Advanced LIGO was scheduled to start 9 am GMT (10 am BST), 14 September 2015. Both gravitational-wave detectors were running fine, but there were few a extra things the calibration team wanted to do and not all the automated analysis had been set up, so it was decided to postpone the start of the run until 18 September. No-one told the Universe. At 9:50 am, 14 September there was an event. To those of us in the Collaboration, it is known as The Event.

The Event’s signal as measured by LIGO Hanford and LIGO Livingston. The shown signal has been filtered to make it more presentable. The Hanford signal is inverted because of the relative orientations of the two interferometers. You can clearly see that both observatories see that same signal, and even without fancy analysis, that there are definitely some wibbles there! Part of Fig. 1 from the Discovery Paper.
Detection
The detectors were taking data and the coherent WaveBurst (cWB) detection pipeline was set up analysing this. It finds triggers in near real time, and so about 3 minutes after the gravitational wave reached Earth, cWB found it. I remember seeing the first few emails… and ignoring them—I was busy trying to finalise details for our default parameter-estimation runs for the start of O1. However, the emails kept on coming. And coming. Something exciting was happening. The detector scientists at the sites swung in to action and made sure that the instruments would run undisturbed so we could get lots of data about their behaviour; meanwhile, the remaining data analysis codes were set running with ruthless efficiency.
The cWB algorithm doesn’t search for a particular type of signal, instead it looks for the same thing in both detectors—it’s what we call a burst search. Burst searches could find supernova explosions, black hole mergers, or something unexpected (so long as the signal is short). Looking at the data, we saw that the frequency increased with time, there was the characteristic chirp of a binary black hole merger! This meant that the searches that specifically look for the coalescence of binaries (black hole or neutron stars) should find it too, if the signal was from a binary black hole. It also meant that we could analyse the data to measure the parameters.

A time–frequency plot that shows The Event’s signal power in the detectors. You can see the signal increase in frequency as time goes on: the characteristic chirp of a binary merger! The fact that you can spot the signal by eye shows how loud it is. Part of Fig. 1 from the Discovery Paper.
The signal was quite short, so it was quick for us to run parameter estimation on it—this makes a welcome change as runs on long, binary neutron-star signals can take months. We actually had the first runs done before all the detection pipelines had finished running. We kept the results secret: the detection people didn’t want to know the results before they looked at their own results (it reminded me of the episode of Whatever Happened to the Likely Lads where they try to avoid hearing the results of the football until they can watch the match). The results from each of the detection pipelines came in [bonus note]. There were the other burst searches: LALInferenceBurst found strong evidence for a signal, and BayesWave classified it clearly as a signal, not noise or a glitch; then the binary searches: both GstLAL and PyCBC found the signal (the same signal) at high significance. The parameter-estimation results were beautiful—we had seen the merger of two black holes!
At first, we couldn’t quite believe that we had actually made the detection. The signal seemed too perfect. Famously, LIGO conducts blind injections: fake signals are secretly put into the data to check that we do things properly. This happened during the run of initial LIGO (an event known as the Big Dog), and many people still remembered the disappointment. We weren’t set up for injections at the time (that was part of getting ready for O1), and the heads of the Collaboration said that there were no plans for blind injections, but people wanted to be sure. Only three or four people in the Collaboration can perform a blind injection; however, it’s a little publicised fact that you can tell if there was an injection. The data from the instruments is recorded at many stages, so there’s a channel which records the injected signal. During a blind-injection run, we’re not allowed to look at this, but this wasn’t a blind-injection run, so this was checked and rechecked. There was nothing. People considered other ways of injecting the signal that wouldn’t be recorded (perhaps splitting the signal up and putting small bits in lots of different systems), but no-one actually understands all the control systems well enough to get this to work. There were basically two ways you could fake the signal. The first is hack into the servers at both sites and CalTech simultaneously and modify the data before it got distributed. You would need to replace all the back-ups and make sure you didn’t leave any traces of tampering. You would also need to understand the control system well enough that all the auxiliary channels (the signal as recorded at over 30 different stages throughout the detectors’ systems) had the right data. The second is to place a device inside the interferometers that would inject the signal. As long as you had a detailed understanding of the instruments, this would be simple: you’d just need to break into both interferometers without being noticed. Since the interferometers are two of the most sensitive machines ever made, this is like that scene from Mission:Impossible, except on the actually impossible difficulty setting. You would need to break into the vacuum tube (by installing an airlock in the concrete tubes without disturbing the seismometers), not disturb the instrument while working on it, and not scatter any of the (invisible) infra-red laser light. You’d need to do this at both sites, and then break in again to remove the devices so they’re not found now that O1 is finished. The devices would also need to be perfectly synchronised. I would love to see a movie where they try to fake the signal, but I am convinced, absolutely, that the easiest way to inject the signal is to collide two black holes a billion years ago. (Also a good plot for a film?)
There is no doubt. We have detected gravitational waves. (I cannot articulate how happy I was to hit the button to update that page! [bonus note])
I still remember the exact moment this hit me. I was giving a public talk on black holes. It was a talk similar to ones I have given many times before. I start with introducing general relativity and the curving of spacetime, then I talk about the idea of a black hole. Next I move on to evidence for astrophysical black holes, and I showed the video zooming into the centre of the Milky Way, ending with the stars orbiting around Sagittarius A*, the massive black hole in the centre of our galaxy (shown below). I said that the motion of the stars was our best evidence for the existence of black holes, then I realised that this was no longer the case. Now, we have a whole new insight into the properties of black holes.
Gravitational-wave astronomy
Having caught a gravitational wave, what do you do with it? It turns out that there’s rather a lot of science you can do. The last few months have been exhausting. I think we’ve done a good job as a Collaboration of assembling all the results we wanted to go with the detection—especially since lots of things were being done for the first time! I’m sure we’ll update our analysis with better techniques and find new ways of using the data, but for now I hope everyone can enjoy what we have discovered so far.
I will write up a more technical post on the results, here we’ll run through some of the highlights. For more details of anything, check out the data release.
The source
The results of our parameter-estimation runs tell us about the nature of the source. We have a binary with objects of masses 


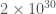

Estimated masses for the two black holes in the binary. 

We know that we’re dealing with compact objects (regular stars could never get close enough together to orbit fast enough to emit gravitational waves at the right frequency), and the only compact objects that can be as massive as these object are black holes. This means we’re discovered the first stellar-mass black hole binary! We’ve also never seen stellar-mass black holes (as opposed to the supermassive flavour that live in the centres of galaxies) this heavy, but don’t get too attached to that record.
Black holes have at most three properties. This makes them much simpler than a Starbucks Coffee (they also stay black regardless of how much milk you add). Black holes are described by their mass, their spin (how much they rotate), and their electric charge. We don’t expect black holes out in the Universe to have much electric charge because (i) its very hard to separate lots of positive and negative charge in the first place, and (ii) even if you succeed at (i), it’s difficult to keep positive and negative charge apart. This is kind of like separating small children and sticky things that are likely to stain. Since the electric charge can be ignored, we just need mass and spin. We’ve measured masses, can we measure spins?
Black hole spins are defined to be between 0 (no spin) and 1 (the maximum amount you can have). Our best estimates are that the bigger black hole has spin 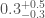

We can’t measure the spins precisely for a few reasons. The signal is short, so we don’t see lots of wibbling while the binaries are orbiting each other (the tell-tale sign of spin). Results for the orientation of the binary also suggest that we’re looking at it either face on or face off, which makes any wobbles in the orbit that are there less visible. However, there is one particular combination of the spins, which we call the effective spin, that we can measure. The effective spin controls how the black holes spiral together. It has a value of 1 if both black holes have max spin values, and are rotating the same way as the binary is orbiting. It has a value of −1 if the black holes have max spin values and are both rotating exactly the opposite way to the binary’s orbit. We find that the effective spin is small, 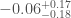
As the two black holes orbit each other, they (obviously, given what we’ve seen) emit gravitational waves. These carry away energy and angular momentum, so the orbit shrinks and the black holes inspiral together. Eventually they merge and settle down into a single bigger black hole. All this happens while we’re watching (we have great seats). A simulation of this happening is below. You can see that the frequency of the gravitational waves is twice that of the orbit, and the video freezes around the merger so you can see two become one.
What are the properties of the final black hole? The mass of the remnant black holes is 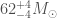
If you do some quick sums, you’ll notice that the final black hole is lighter than the sum of the two initial black holes. This is because of that energy that was carried away by the gravitational waves. Over the entire evolution of the system, 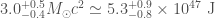

We’ve measured mass, what about spin? The final black hole’s spin in 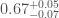
We have measured both of the properties of the final black hole, and we have done this using spacetime itself. This is astounding!

Estimated mass 

How big is the final black hole? My colleague Nathan Johnson-McDaniel has done some calculations and finds that the total distance around the equator of the black hole’s event horizon is about 
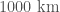

OK, we’ve covered the properties of the black holes, perhaps it’s time for a celebratory biscuit and a sit down? But we’re not finished yet, where is the source?
We infer that the source is at a luminosity distance of 
With only the two LIGO detectors in operation, it is difficult to localise where on the sky source came from. To have a 90% chance of finding the source, you’d need to cover 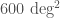
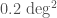
Astrophysics
The detection of this black hole merger tells us:
- Black holes 30 times the mass of our Sun do form These must be the remains of really massive stars. Stars lose mass throughout their lifetime through stellar winds. How much they lose depends on what they are made from. Astronomers have a simple periodic table: hydrogen, helium and metals. (Everything that is not hydrogen or helium is a metal regardless of what it actually is). More metals means more mass loss, so to end up with our black holes, we expect that they must have started out as stars with less than half the fraction of metals found in our Sun. This may mean the parent stars were some of the first stars to be born in the Universe.
- Binary black holes exist There are two ways to make a black hole binary. You can start with two stars in a binary (stars love company, so most have at least one companion), and have them live their entire lives together, leaving behind the two black holes. Alternatively, you could have somewhere where there are lots of stars and black holes, like a globular cluster, and the two black holes could wander close enough together to form the binary. People have suggested that either (or both) could happen. You might be able to tell the two apart using spin measurements. The spins of the black holes are more likely to be aligned (with each other and the way that the binary orbits) if they came from stars formed in a binary. The spins would be randomly orientated if two black holes came together to form a binary by chance. We can’t tell the two apart now, but perhaps when we have more observations!
- Binary black holes merge Since we’ve seen a signal from two black holes inspiralling together and merging, we know that this happens. We can also estimate how often this happens, given how many signals we’ve seen in our observations. Somewhere in the observable Universe, a similar binary could be merging about every 15 minutes. For LIGO, this should mean that we’ll be seeing more. As the detectors’ sensitivity improves (especially at lower frequencies), we’ll be able to detect more and more systems [bonus note]. We’re still uncertain in our predictions of exactly how many we’ll see. We’ll understand things better after observing for longer: were we just lucky, or were we unlucky not to have seen more? Given these early results, we estimate that the end of the third observing run (O3), we could have over 30. It looks like I will be kept busy over the next few years…
Gravitational physics
Black holes are the parts of the Universe with the strongest possible gravity. They are the ideal place to test Einstein’s theory of general relativity. The gravitational waves from a black hole merger let us probe right down to the event horizon, using ripples in spacetime itself. This makes gravitational waves a perfect way of testing our understanding of gravity.
We have run some tests on the signal to see how well it matches our expectations. We find no reason to doubt that Einstein was right.
The first check is that if we try to reconstruct the signal, without putting in information about what gravitational waves from a binary merger look like, we find something that agrees wonderfully with our predictions. We can reverse engineer what the gravitational waves from a black hole merger look like from the data!

Recovered gravitational waveforms from our analysis of The Event. The dark band shows our estimate for the waveform without assuming a particular source (it is build from wavelets, which sound adorable to me). The light bands show results if we assume it is a binary black hole (BBH) as predicted by general relativity. They match really well! Fig. 6 from the Parameter Estimation Paper.
As a consistency test, we checked what would happen if you split the signal in two, and analysed each half independently with our parameter-estimation codes. If there’s something weird, we would expect to get different results. We cut the data into a high frequency piece and a low frequency piece at roughly where we think the merger starts. The lower frequency (mostly) inspiral part is more similar to the physics we’ve tested before, while the higher frequency (mostly) merger and ringdown is new and hence more uncertain. Looking at estimates for the mass and spin of the final black hole, we find that the two pieces are consistent as expected.
In general relativity, gravitational waves travel at the speed of light. (The speed of light is misnamed, it’s really a property of spacetime, rather than of light). If gravitons, the theoretical particle that carries the gravitational force, have a mass, then gravitational waves can’t travel at the speed of light, but would travel slightly slower. Because our signals match general relativity so well, we can put a limit on the maximum allowed mass. The mass of the graviton is less than 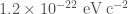

Bounds on the Compton wavelength 
Overall things look good for general relativity, it has passed a tough new test. However, it will be extremely exciting to get more observations. Then we can combine all our results to get the best insights into gravity ever. Perhaps we’ll find a hint of something new, or perhaps we’ll discover that general relativity is perfect? We’ll have to wait and see.
Conclusion
100 years after Einstein predicted gravitational waves and Schwarzschild found the equations describing a black hole, LIGO has detected gravitational waves from two black holes orbiting each other. This is the culmination of over forty years of effort. The black holes inspiral together and merge to form a bigger black hole. This is the signal I would have wished for. From the signal we can infer the properties of the source (some better than others), which makes me exceedingly happy. We’re starting to learn about the properties of black holes, and to test Einstein’s theory. As we continue to look for gravitational waves (with Advanced Virgo hopefully joining next year), we’ll learn more and perhaps make other detections too. The era of gravitational-wave astronomy has begun!
After all that, I am in need of a good nap! (I was too excited to sleep last night, it was like a cross between Christmas Eve and the night before final exams). For more on the story from scientists inside the LIGO–Virgo Collaboration, check out posts by:
- Matt Pitkin (the tireless reviewer of our parameter-estimation work)
- Brynley Pearlstone (who’s just arrived at the LIGO Hanford site)
- Amber Stuver (who blogged through LIGO’s initial runs too)
- Rebecca Douglas (a good person to ask about what build a detector out of)
- Daniel Williams (someone fresh to the Collaboration)
- Sean Leavey (a PhD student working on on interferometry)
- Andrew Williamson (who likes to look for gravitational waves that coincide with gamma-ray bursts)
- Shane Larson (another fan of space-based gravitational-wave detectors)
- Roy Williams (who helps to make all the wonderful open data releases for LIGO)
- Chris North (creator of the Gravoscope amongst other things)
There’s also this video from my the heads of my group in Birmingham on their reactions to the discovery (the credits at the end show how large an effort the detection is).
Discovery paper: Observation of Gravitational Waves from a Binary Black Hole Merger
Date release: LIGO Open Science Center
Bonus notes
Search pipelines
At the Large Hadron Collider, there are separate experiments that independently analyse data, and this is an excellent cross-check of any big discoveries (like the Higgs). We’re not in a position to do this for gravitational waves. However, the different search pipelines are mostly independent of each other. They use different criteria to rank potential candidates, and the burst and binary searches even look for different types of signals. Therefore, the different searches act as a check of each other. The teams can get competitive at times, so they do check each other’s results thoroughly.
The announcement
Updating Have we detected gravitational waves yet? was doubly exciting as I had to successfully connect to the University’s wi-fi. I managed this with about a minute to spare. Then I hovered with my finger on the button until David Reitze said “We. Have detected. Gravitational waves!” The exact moment is captured in the video below, I’m just off to the left.

The moment of the announcement of the first observation of gravitational waves at the University of Birmingham. Credit: Kat Grover
Parameters and uncertainty
We don’t get a single definite number from our analysis, we have some uncertainty too. Therefore, our results are usually written as the median value (which means we think that the true value is equally probable to be above or below this number), plus the range needed to safely enclose 90% of the probability (so there’s a 10% chance the true value is outside this range. For the mass of the bigger black hole, the median estimate is 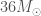
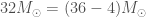

Sensitivity and ranges
Gravitational-wave detectors measure the amplitude of the wave (the amount of stretch and squash). The measured amplitude is smaller for sources that are further away: if you double the luminosity distance of a source, you halve its amplitude. Therefore, if you improve your detectors’ sensitivity by a factor of two, you can see things twice as far away. This means that we observe a volume of space (2 × 2 × 2) = 8 times as big. (This isn’t exactly the case because of pesky factors from the expansion of the Universe, but is approximately right). Even a small improvement in sensitivity can have a considerable impact on the number of signals detected!
 , and their antiparticle equivalents (antineutrinos) are denoted by
, and their antiparticle equivalents (antineutrinos) are denoted by  . We’ll not worry about the difference between the two. Neutrinos are rather shy. They are quite happy doing their own thing, and don’t interact much with other particles. They don’t have an electric charge (they are neutral), so they don’t play with the electromagnetic force (and photons), they also don’t do anything with the strong force (and gluons). They only get involved with the weak force (W and Z bosons). As you might expect from the name, the weak force doesn’t do much (it only operates over short distances), so spotting a neutrino is a rare occurrence.
. We’ll not worry about the difference between the two. Neutrinos are rather shy. They are quite happy doing their own thing, and don’t interact much with other particles. They don’t have an electric charge (they are neutral), so they don’t play with the electromagnetic force (and photons), they also don’t do anything with the strong force (and gluons). They only get involved with the weak force (W and Z bosons). As you might expect from the name, the weak force doesn’t do much (it only operates over short distances), so spotting a neutrino is a rare occurrence.
 , the muon-neutrino
, the muon-neutrino 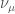 (
( is the Greek letter mu) and the tau-neutrino
is the Greek letter mu) and the tau-neutrino  (
( is the Greek letter tau).
is the Greek letter tau).
 ), which are the nuclei of hydrogen, are converted to Helium nuclei after a sequence of steps. Electron neutrinos
), which are the nuclei of hydrogen, are converted to Helium nuclei after a sequence of steps. Electron neutrinos 




 ), a boy and a girl (
), a boy and a girl ( ), a girl and a boy (
), a girl and a boy ( ) and two boys (
) and two boys ( ). The probability of having a boy is almost identical to having a girl, so let’s keep things simple and assume that all four options have equal probability.
). The probability of having a boy is almost identical to having a girl, so let’s keep things simple and assume that all four options have equal probability. ; (ii) the probability of having a boy and a girl is
; (ii) the probability of having a boy and a girl is  , and (iii) the probability of having two boys is
, and (iii) the probability of having two boys is 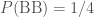 .
. ), another girl and then Lucy (
), another girl and then Lucy ( ), Lucy and then a boy (
), Lucy and then a boy ( ) or a boy and then Lucy (
) or a boy and then Lucy ( ). Since the sex of children are not linked (if we ignore the possibility of identical twins), each of these are equally probable. Therefore, (i)
). Since the sex of children are not linked (if we ignore the possibility of identical twins), each of these are equally probable. Therefore, (i) 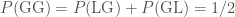 ; (ii)
; (ii)  , and (iii)
, and (iii) 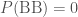 . We have ruled out one possibility, and changed the probability having two girls.
. We have ruled out one possibility, and changed the probability having two girls. ; (ii)
; (ii)  , and (iii)
, and (iii) 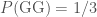 ; (ii)
; (ii)  , and (iii)
, and (iii)  . Hence, the probability it is left is
. Hence, the probability it is left is  . Since there are six doughnuts left, the probability you’ll pick the nemesis doughnut next is
. Since there are six doughnuts left, the probability you’ll pick the nemesis doughnut next is  . Equally, you could have figured that out by realising that it’s equally probable that the nemesis doughnut is any of the eighteen that you’ve not eaten.
. Equally, you could have figured that out by realising that it’s equally probable that the nemesis doughnut is any of the eighteen that you’ve not eaten. , the probability that she unluckily picked a different flavour is
, the probability that she unluckily picked a different flavour is  . If we were lucky, the probability that we managed to get down to there being four left is
. If we were lucky, the probability that we managed to get down to there being four left is 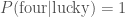 , we were guaranteed not to eat it! If we were unlucky, that the bad one is amongst the remaining eleven, the probability of getting down to four is
, we were guaranteed not to eat it! If we were unlucky, that the bad one is amongst the remaining eleven, the probability of getting down to four is  . The total probability of getting down to four is
. The total probability of getting down to four is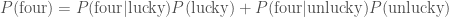 .
. .
.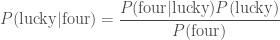 ,
,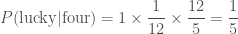 .
.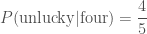 .
. and
and  .
. ;
; ;
;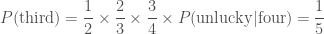 ,
, .
.

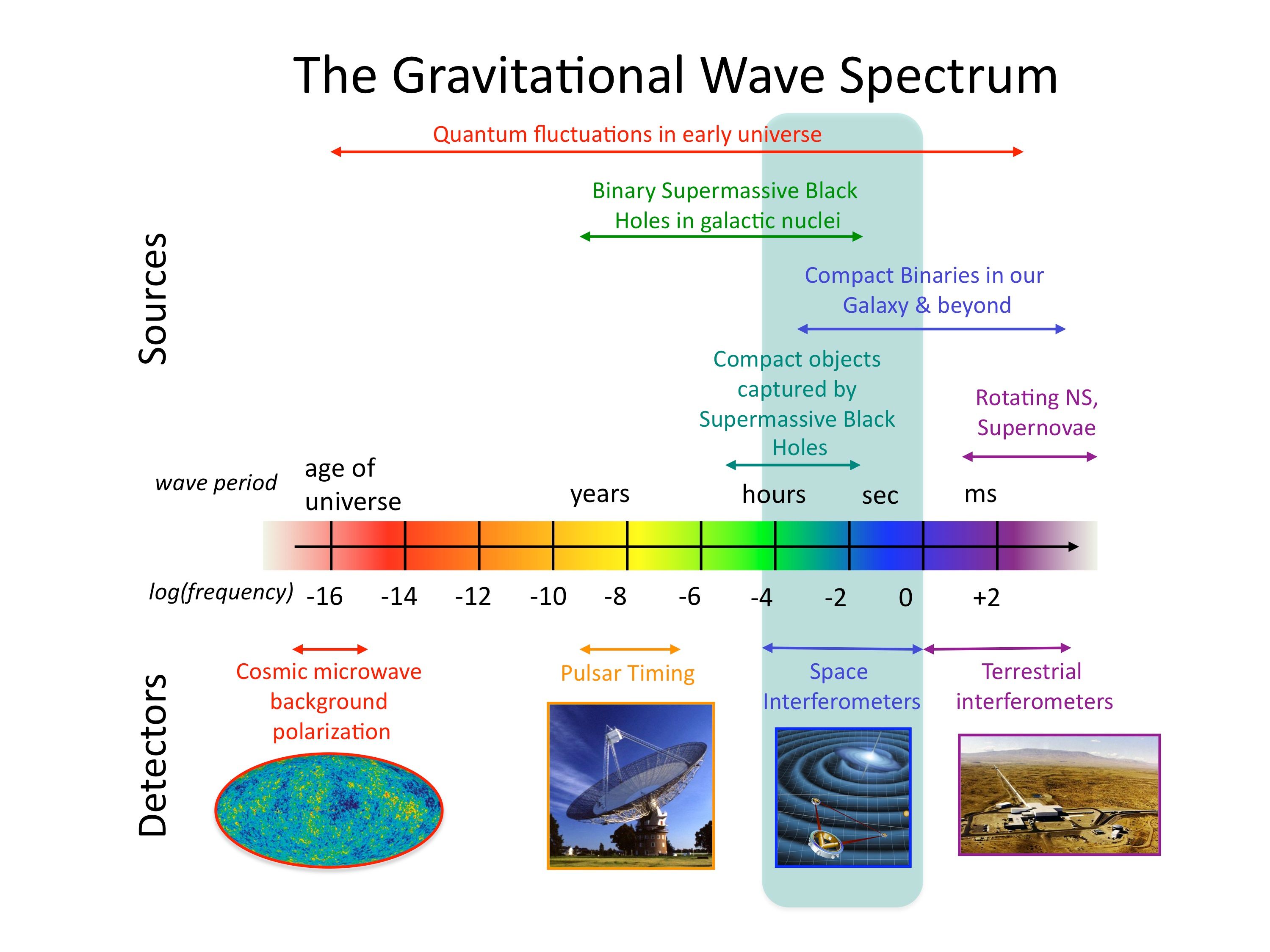
 that is really convenient if you’re a cosmologist, but a pain for anyone else. It does have the advantage of making the pulsar timing arrays look more sensitive though.
that is really convenient if you’re a cosmologist, but a pain for anyone else. It does have the advantage of making the pulsar timing arrays look more sensitive though.
 to mean the probability of
to mean the probability of  . A joint probability describes the probability of two (or more things), so we have
. A joint probability describes the probability of two (or more things), so we have  as the probability that both
as the probability that both  happen. The probability that
happen. The probability that  . Consider the the joint probability of
. Consider the the joint probability of 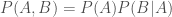 .
. .
. .
. ,
, . We normally have a model that can predict how likely it would be to observe that data if our hypothesis is true, so we know
. We normally have a model that can predict how likely it would be to observe that data if our hypothesis is true, so we know  , so we just need to convert between the two. This is known as the inverse problem.
, so we just need to convert between the two. This is known as the inverse problem. .
.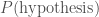 is the prior, because it’s what we believed about our hypothesis before we got the data, and
is the prior, because it’s what we believed about our hypothesis before we got the data, and  is the evidence. If ever you hear of someone doing something in a Bayesian way, it just means they are using the formula above. I think it’s rather silly to point this out, as it’s really the only logical way to do science, but people like to put “Bayesian” in the
is the evidence. If ever you hear of someone doing something in a Bayesian way, it just means they are using the formula above. I think it’s rather silly to point this out, as it’s really the only logical way to do science, but people like to put “Bayesian” in the  .
. . The prior probability of not having the disease is
. The prior probability of not having the disease is  . The likelihood of our positive result is
. The likelihood of our positive result is  , which seems worrying. The evidence, the total probability of testing positive
, which seems worrying. The evidence, the total probability of testing positive 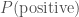 is found by adding the probability of a true positive and a false positive
is found by adding the probability of a true positive and a false positive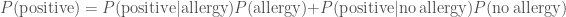 .
. . We thus have everything we need. Substituting everything in, gives
. We thus have everything we need. Substituting everything in, gives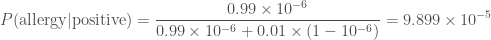 .
.
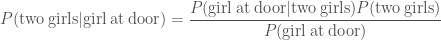 .
. . If we assume that it is equally likely that any one of the children opened the door, then the likelihood that one of the girls did so when their are two of them is
. If we assume that it is equally likely that any one of the children opened the door, then the likelihood that one of the girls did so when their are two of them is  . Similarly, if there were two boys, the probability of a girl answering the door is
. Similarly, if there were two boys, the probability of a girl answering the door is  . The evidence, the total probability of a girl being at the door is
. The evidence, the total probability of a girl being at the door is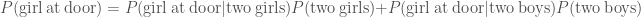 .
. .
. .
. , makes a difference. We know the probability of surviving the fatal dose is
, makes a difference. We know the probability of surviving the fatal dose is 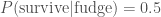 . The evidence, the total probability of surviving
. The evidence, the total probability of surviving  , is calculated by considering the two possible sequence of events: either Ted ate the fudge and survived or he didn’t eat the fudge and survived
, is calculated by considering the two possible sequence of events: either Ted ate the fudge and survived or he didn’t eat the fudge and survived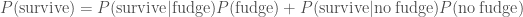 .
. . Since Ted either ate the fudge or he didn’t
. Since Ted either ate the fudge or he didn’t 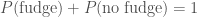 . Therefore,
. Therefore,![P(\mathrm{survive}) = 0.5 P(\mathrm{fudge}) + [1 - P(\mathrm{fudge})] = 1 - 0.5 P(\mathrm{fudge})](https://s0.wp.com/latex.php?latex=P%28%5Cmathrm%7Bsurvive%7D%29+%3D+0.5+P%28%5Cmathrm%7Bfudge%7D%29+%2B+%5B1+-+P%28%5Cmathrm%7Bfudge%7D%29%5D+%3D+1+-+0.5+P%28%5Cmathrm%7Bfudge%7D%29&bg=ffffff&fg=444444&s=0&c=20201002) .
. .
. . In this case,
. In this case, .
. . In this case we are in a state of ignorance. Our posterior is
. In this case we are in a state of ignorance. Our posterior is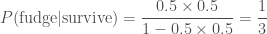 .
. .
. .
.


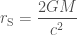 ,
, is the black hole’s mass (as it increases, so does the size of the event horizon);
is the black hole’s mass (as it increases, so does the size of the event horizon); 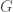 is
is  ). You can plug in some numbers to this formula (if anything like me, two or three times before getting the correct answer), to find out how big a black hole is (or equivalently, how much you need to squeeze something before it will collapse to a black hole).
). You can plug in some numbers to this formula (if anything like me, two or three times before getting the correct answer), to find out how big a black hole is (or equivalently, how much you need to squeeze something before it will collapse to a black hole).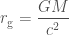 .
.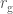 . An interesting consequence of this (well, something I think is interesting), is to consider the effective density of a black hole. Density is how much mass you can fit into a given space. In our case, we’ll consider the mass of the black hole and the volume of its event horizon. This would be something like
. An interesting consequence of this (well, something I think is interesting), is to consider the effective density of a black hole. Density is how much mass you can fit into a given space. In our case, we’ll consider the mass of the black hole and the volume of its event horizon. This would be something like ,
, for density and you shouldn’t worry about the factors of
for density and you shouldn’t worry about the factors of  or
or 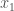 ,
, 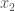 , etc., or as
, etc., or as  where the subscript
where the subscript  is used as shorthand to indicate any of the possible outcomes. The probability of the numeric value being a particular
is used as shorthand to indicate any of the possible outcomes. The probability of the numeric value being a particular  . For rolling our dice, the outcomes are one to six (
. For rolling our dice, the outcomes are one to six ( ,
,  , etc.) and the probabilities are
, etc.) and the probabilities are .
.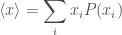 ,
, means
means 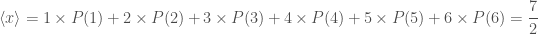 .
.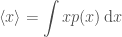 ,
,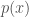 is the probability density function.
is the probability density function.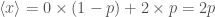 ,
, is less than one, so if
is less than one, so if  , it’s worth playing. If we were tossing a (fair) coin, we’d expect to come out even, if we had to roll a six, we’d expect to pay more.
, it’s worth playing. If we were tossing a (fair) coin, we’d expect to come out even, if we had to roll a six, we’d expect to pay more. . Imagine each outcome
. Imagine each outcome  times, then the mean is
times, then the mean is .
. so that
so that  .
. . This can be done by adding up probabilities until you get a half
. This can be done by adding up probabilities until you get a half .
. ,
,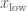 is the lower limit of the distribution. (That’s all the calculus out of the way now, so if you’re not a fan you can relax). The
is the lower limit of the distribution. (That’s all the calculus out of the way now, so if you’re not a fan you can relax). The  .
. .
. and
and  to describe horizontal and vertical position respectively. Cartesian coordinates give you a nice grid with everything at right-angles. Undergrad students often like to stick with Cartesian coordinates as they are straight-forward and familiar. However, they can be a pain when describing a circle. If we want to plot a line five units from the origin of of coordinate system
to describe horizontal and vertical position respectively. Cartesian coordinates give you a nice grid with everything at right-angles. Undergrad students often like to stick with Cartesian coordinates as they are straight-forward and familiar. However, they can be a pain when describing a circle. If we want to plot a line five units from the origin of of coordinate system  , we have to solve
, we have to solve 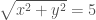 . However, if we used a
. However, if we used a 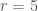 . By using coordinates that match the symmetry of our system we greatly simplify the problem!
. By using coordinates that match the symmetry of our system we greatly simplify the problem!

 . By understanding symmetries, we can formulate our analysis of the problem such that we ask the best questions.
. By understanding symmetries, we can formulate our analysis of the problem such that we ask the best questions.
{kind=link}