We use probabilities a lot in science. Previously, I introduced the concept of probabilities, here I’ll explain the concept of expectation and averages. Expectation and average values are one of the most useful statistics that we can construct from a probability distribution. This post contains a traces of calculus, but is peanut free.
Expectations
Imagine that we have a discrete set of numeric outcomes, such as the number from rolling a die. We’ll label these as 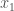
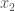






The expectation value is the sum of all the possible outcomes multiplied by their respective probabilities,
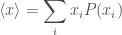
where 
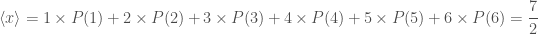
The expectation value of a distribution is its average, the value you’d expect after many (infinite) repetitions. (Of course this is possible in reality—you’d certainly get RSI—but it is useful for keeping statisticians out of mischief).
For a continuous distribution, the expectation value is given by
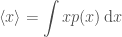
where 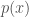
You can use the expectation value to guide predictions for the outcome. You can never predict with complete accuracy (unless there is only one possible outcome), but you can use knowledge of the probabilities of the various outcomes the inform your predictions.
Imagine that after buying a large quantity of fudge, for entirely innocent reasons, the owner offers you the chance to play double-or-nothing—you’ll either pay double the bill or nothing, based on some random event—should you play? Obviously, this depends upon the probability of winning. Let’s say that the probability of winning is 
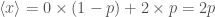
where I’m working in terms of unified fudge currency, which, shockingly, is accepted in very few shops, but has the nice property that your fudge bill is always 1. Anyhow, if 

The expectation value is the equivalent of the mean. This is the average that people usually think of first. If you have a set of numeric results, you calculate the mean by adding up all or your results and dividing by the total number of results 


We can estimate the probability of each outcome as 

Median and mode
Aside from the mean there are two other commonly used averages, the median and the mode. These aren’t quite as commonly used, despite sounding friendlier. With a set of numeric results, the median is the middle result and the mode is the most common result. We can define equivalents for both when dealing with probability distributions.
To calculate the median we find the value where the total probability of being smaller (or bigger) than it is a half: 

For a continuous distribution this becomes

where 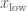
The median is often used as it is not as sensitive as the mean to a few outlying results which are far from the typical values.
The mode is the value with the largest probability, the most probable outcome

For a continuous distribution, it is the point which maximises the probability density function

The modal value is the most probable outcome, the most likely result, the one to bet on if you only have one chance.
Education matters
Every so often, some official, usually an education minister, says something about wanting more than half of students to be above average. This results in much mocking, although seemingly little rise in the standards for education ministers. Having discussed averages ourselves, we can now see if it’s entirely fair to pick on these poor MPs.
The first line of defence, is that we should probably specify the distribution we’ve averaging. It may well be that they actually meant the average bear. It’s a sad truth that bears perform badly in formal education. Many blame the unfortunate stereotyping resulting from Winnie the Pooh. It might make sense to compare with performance in the past to see if standards are improving. We could imagine that taking the average from the 1400s would indeed show some improvement. For argument’s sake, let’s say that we are indeed talking about the average over this year’s students.
If the average we were talking about was the median, then it would be impossible for more (or fewer) than half of students to do better than average. In the case, it is entirely fair to mock the minister, and possibly to introduce them to the average bear. In this case, a mean bear.
If we were referring to the mode, then it is quite simple for more than half of the students to do better than this. To achieve this we just need a bottom-heavy distribution, a set of results where the most likely outcome is low, but most students do better than this. We might want to question an education system where the aim is to have a large number of students doing poorly though!
Finally, there is the mean; to use the mean, we first have to decide if we have a sensible if we are averaging a sensible quantity. For education performance this normally means exam results. Let’s sidestep the issue of if we want to reduce the output of the education system down to a single number, and consider the properties we want in order to take a sensible average. We want the results to be numeric (check); to be ordered, such that high is good and low is bad (or vice versa) so 42 is better than 41 but not as good as 43 and so on (check), and to be on a linear scale. The last criterion means that performance is directly proportional to the mark: a mark twice as big is twice as good. Most exams I’ve encountered are not like this, but I can imagine that it is possible to define a mark scheme this way. Let’s keep imagining, and assume things are sensible (and perhaps think about kittens and rainbows too… ).
We can construct a distribution where over half of students perform better than the mean. In this case we’d really need a long tail: a few students doing really very poorly. In this case, these few outliers are enough to skew the mean and make everyone else look better by comparison. This might be better than the modal case where we had a glut of students doing badly, as now we can have lots doing nicely. However, it also means that there are a few students who are totally failed by the system (perhaps growing up to become a minister for education), which is sad.
In summary, it is possible to have more than 50% of students performing above average, assuming that we are not using the median. It’s therefore unfair to heckle officials with claims of innumeracy. However, for these targets to be met requires lots of students to do badly. This seems like a poor goal. It’s probably better to try to aim for a more sensible distribution with about half of students performing above average, just like you’d expect.
