One of the great discoveries that came with our first observation of gravitational waves was that black holes can merge—two black holes in a binary can come together and form a bigger black hole. This had long been predicted, but never before witnessed. If black holes can merge once, can they go on to merge again? In this paper, we calculated how to identify a binary containing a second-generation black hole formed in a merger.
Merging black holes
Black holes have two important properties: their mass and their spin. When two black holes merge, the resulting black hole has:
- A mass which is almost as big as the sum of the masses of its two parents. It is a little less (about 5%) as some of the energy is radiated away as gravitational waves.
- A spin which is around 0.7. This is set by the angular momentum of the two black holes as they plunge in together. For equal-mass black holes, the orbit of the two black holes will give about enough angular momentum for the final black hole to be about 0.7. The spins of the two parent black holes will cause a bit a variation around this, depending upon the orientations of their spins. For more unequal mass binaries, the spin of the larger parent black hole becomes more important.
To look for second-generation (or higher) black holes formed in mergers, we need to look for more massive black holes with spins of about 0.7 [bonus note].

Combining black holes. The result of a merger is a larger black hole with significant spin. From Dawn Finney.
The difficult bit here is that we don’t know the distribution of masses and spins of the initial first-generation black holes. What is they naturally form with spins of 0.7? How can you tell if a black hole is unexpectedly large if you don’t know what sizes to expect? With the discovery of the 10 binary black holes found in our first and second observing runs, we are able to start making inferences about the properties of black holes—using these measurements of the population, we can estimate how probable it is that a binary contains a second generation black hole versus containing two first generation black hole.
GW170729
Amongst the black holes observed in O1 and O2, the source of GW170729 stands out. It is both the most massive, and one of only two systems (the other being GW151226) showing strong evidence for spin. This got me wondering if it could be a second-generation system? The high mass would be explained as we have a second-generation black hole, and the spin is larger than usual as a spin 0.7 sticks out.
Chase Kimball worked out the relative probability of getting a system with a given chirp mass and effective inspiral spin for a binary with a second-generation black hole verses a binary with only first-generation black holes. We worked in terms of chirp mass and effective inspiral spin, as these are the properties we measure well from a gravitational-wave signal.
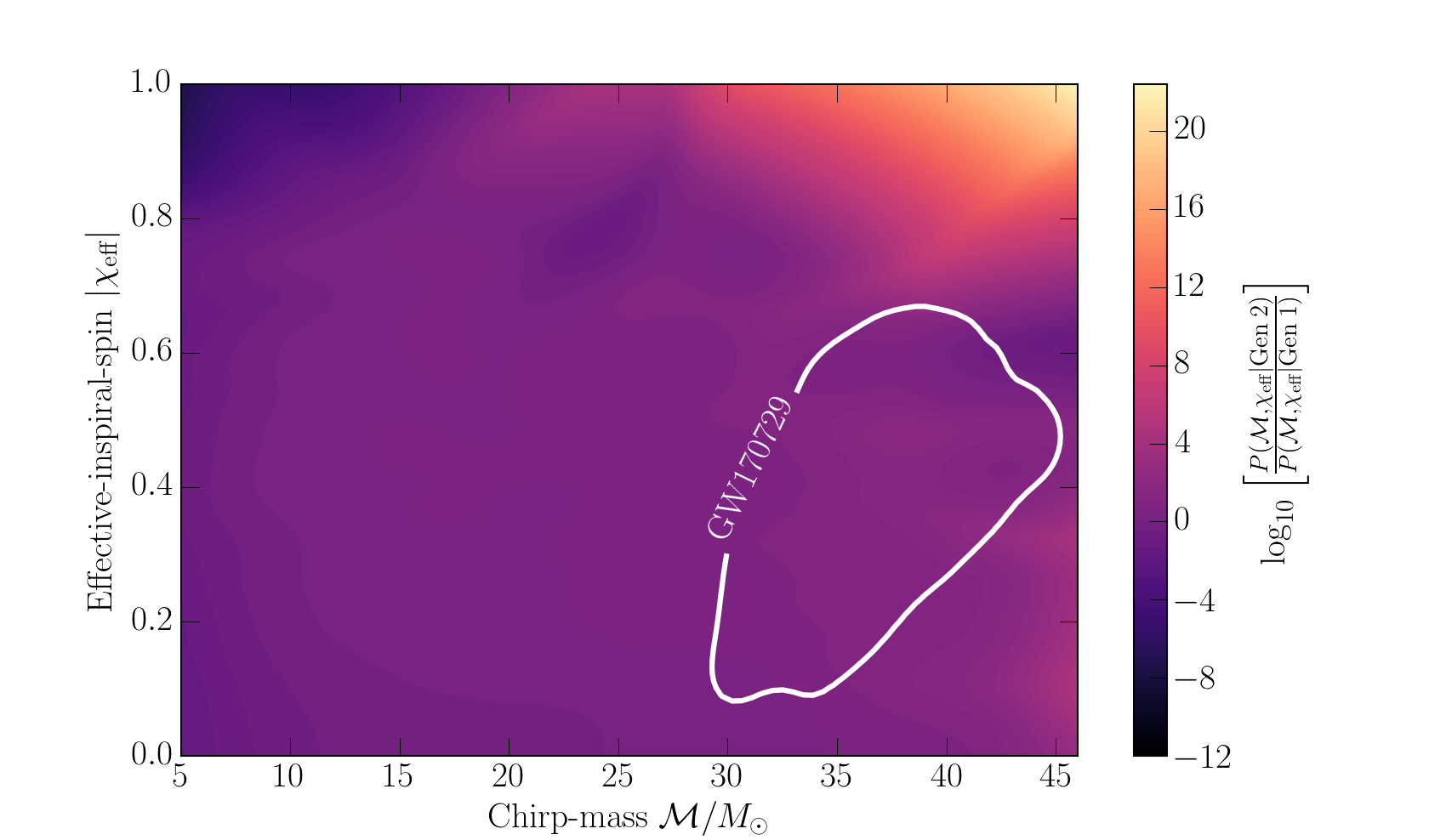
Relative likelihood of a binary black hole being second-generation versus first-generation for different values of the chirp mass and the magnitude of the effective inspiral spin. The white contour gives the 90% credible area for GW170729. Figure 1 of Kimball et al. (2019).
The plot above shows the relative probabilities. Yellow indicate chirp mass and effective inspiral spins which are more likely with second-generation systems, while dark purple indicates values more likely with first-generation systems.. The first thing I realised was my idea about the spin was off. We expect binaries with second-generation black holes to be formed dynamically. Following the first merger, the black hole wander around until it gets close enough to form a new binary with a new black hole. For dynamically formed binaries the spins should be randomly distributed. This means that there’s only a small probability of having a spin aligned with the orbital angular momentum as measured for GW170729. Most of the time, you’d measure an effective inspiral spin of around zero.
Since we don’t know exactly the chirp mass and effective inspiral spin for GW170729, we have to average over our uncertainty. That gives the ratio of the probability of observing GW170729 given a second-generation source, verses given a first-generation source. Using different inferred black hole populations (for example, ones inferred including and excluding GW170729), we find ratios of between 0.2 (meaning the first-generation origin is more likely) and 16 (meaning second generation is more likely). The results change significantly as the result is sensitive to the maximum mass of a black hole. If we include GW170729 in our population inference for first-generation systems, the maximum mass goes up, and it’s easier to explain the system as first-generation (as you’d expect).
Before you place your bets, there is one more piece to the calculation. We have calculated the relative probabilities of the observed properties assuming either first-generation black holes or a second-generation black hole, but we have not folded in the relative rates of mergers [bonus note]. We expect first-generation only binaries to be more common than ones containing second generation black holes. In simulations of globular clusters, at most about 20% of merging binaries are with second-generation black holes. For binaries not in an environment like a globular cluster (where there are lots of nearby black holes to grab), we expect the fraction of second-generation black holes in binaries to be basically zero. Therefore, on balance we have at best a weak preference for a second-generation black hole and most probably just two first-generation black holes in GW170729’s source, despite its large mass.
Verdict
What we have learnt from this calculation is that it seems that all of the first 10 binary black holes contain only first-generation black holes. It is safe to infer the properties of first-generation black holes from these observations. Detecting second-generation black holes requires knowledge of this distribution, and crucially if there is a maximum mass. As we get more detection, we’ll be able to pin this down. There is still a lot to learn about the full black hole family.
If you’d like to understand our calculation, the paper is extremely short. It is therefore an excellent paper to bring to journal club if you are a PhD student who forgot you were presenting this week…
arXiv: 1903.07813 [astro-ph.HE]
Journal: Research Notes of the AAS; 4(1):2; 2020 [bonus note]
Gizmodo story: The gravitational wave detectors are turning back on and we’re psyched
Theme music: Nice to see you!
Bonus notes
Useful papers
Back in 2017 two papers hit the arXiv [bonus bonus note] at pretty much the same time addressing the expected properties of second-generation black holes: Fishbach, Holz & Farr (2017), and Gerosa & Berti (2017). Both are nice reads.
I was asked how we could tell if the black holes we were seeing were themselves the results of mergers back in 2016 when I was giving a talk to the Carolian Astronomical Society. It was a good question. I explained about the masses and spins, but I didn’t think about how to actually do the analysis to infer if we had a merger. I now make a note to remember any questions I’m asked, as they can be good inspiration for projects!
Bayes factor and odds ratio
The quantity we work out in the paper is the Bayes factor for a second-generation system verses a first-generation one
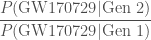
What we want is the odds ratio
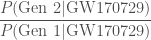
which gives the betting odds for the two scenarios. The convert the Bayes factor into an odds ratio we need the prior odds

We’re currently working on a better way to fold these pieces together.
1000 words
As this was a quick calculation, we thought it would be a good paper to be a Research Note. Research Notes are limited to 1000 words, which is a tough limit. We carefully crafted the document, using as many word-saving measures (such as abbreviations), as we could. We made it to the limit by our counting, only to submit and find that we needed to share another 100 off! Fortunately, the arXiv [bonus bonus note] is more forgiving, so you can read our more relaxed (but still delightfully short) version there. It’s the one I’d recommend.
arXiv
For those reading who are not professional physicists, the arXiv (pronounced archive, as the X is really the Greek letter chi χ) is a preprint server. It where physicists can post version of their papers ahead of publication. This allows sharing of results earlier (both good as it can take a while to get a final published paper, and because you can get feedback before finalising a paper), and, vitally, for free. Most published papers require a subscription to read. Fine if you’re at a university, not so good otherwise. The arXiv allows anyone to read the latest research. Admittedly, you have to be careful, as not everything on the arXiv will make it through peer review, and not everyone will update their papers to reflect the published version. However, I think the arXiv is a very good thing™. There are few things I can think of which have benefited modern science as much. I would 100% support those behind the arXiv receiving a Nobel Prize, as I think it has had just as a significant impact on the development of the field as the discovery of dark matter, understanding nuclear fission, or deducing the composition of the Sun.
 –
– , which is about
, which is about  –
–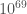
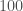 –
–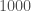 galaxies.
galaxies.


 is inversely proportional to the sixth power of the signal-to-noise ration
is inversely proportional to the sixth power of the signal-to-noise ration  . This is what you would expect. The localization volume depends upon the angular uncertainty on the sky
. This is what you would expect. The localization volume depends upon the angular uncertainty on the sky  , the distance to the source
, the distance to the source  , and the distance uncertainty
, and the distance uncertainty  ,
, .
.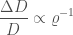 .
.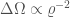 .
.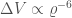 .
. ), a boy and a girl (
), a boy and a girl ( ), a girl and a boy (
), a girl and a boy ( ) and two boys (
) and two boys ( ). The probability of having a boy is almost identical to having a girl, so let’s keep things simple and assume that all four options have equal probability.
). The probability of having a boy is almost identical to having a girl, so let’s keep things simple and assume that all four options have equal probability. ; (ii) the probability of having a boy and a girl is
; (ii) the probability of having a boy and a girl is  , and (iii) the probability of having two boys is
, and (iii) the probability of having two boys is 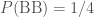 .
. ), another girl and then Lucy (
), another girl and then Lucy ( ), Lucy and then a boy (
), Lucy and then a boy (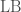 ) or a boy and then Lucy (
) or a boy and then Lucy ( ). Since the sex of children are not linked (if we ignore the possibility of identical twins), each of these are equally probable. Therefore, (i)
). Since the sex of children are not linked (if we ignore the possibility of identical twins), each of these are equally probable. Therefore, (i) 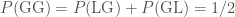 ; (ii)
; (ii)  , and (iii)
, and (iii) 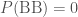 . We have ruled out one possibility, and changed the probability having two girls.
. We have ruled out one possibility, and changed the probability having two girls. ; (ii)
; (ii)  , and (iii)
, and (iii) 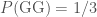 ; (ii)
; (ii)  , and (iii)
, and (iii)  . Hence, the probability it is left is
. Hence, the probability it is left is  . Since there are six doughnuts left, the probability you’ll pick the nemesis doughnut next is
. Since there are six doughnuts left, the probability you’ll pick the nemesis doughnut next is  . Equally, you could have figured that out by realising that it’s equally probable that the nemesis doughnut is any of the eighteen that you’ve not eaten.
. Equally, you could have figured that out by realising that it’s equally probable that the nemesis doughnut is any of the eighteen that you’ve not eaten. , the probability that she unluckily picked a different flavour is
, the probability that she unluckily picked a different flavour is  . If we were lucky, the probability that we managed to get down to there being four left is
. If we were lucky, the probability that we managed to get down to there being four left is 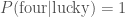 , we were guaranteed not to eat it! If we were unlucky, that the bad one is amongst the remaining eleven, the probability of getting down to four is
, we were guaranteed not to eat it! If we were unlucky, that the bad one is amongst the remaining eleven, the probability of getting down to four is  . The total probability of getting down to four is
. The total probability of getting down to four is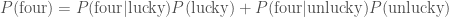 .
. .
.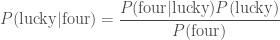 ,
,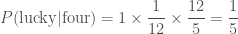 .
.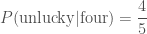 .
. and
and  .
. ;
; ;
;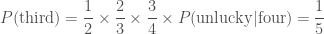 ,
, .
. to mean the probability of
to mean the probability of  . A joint probability describes the probability of two (or more things), so we have
. A joint probability describes the probability of two (or more things), so we have  as the probability that both
as the probability that both  happen. The probability that
happen. The probability that  . Consider the the joint probability of
. Consider the the joint probability of 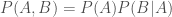 .
. .
. .
. ,
, . We normally have a model that can predict how likely it would be to observe that data if our hypothesis is true, so we know
. We normally have a model that can predict how likely it would be to observe that data if our hypothesis is true, so we know  , so we just need to convert between the two. This is known as the inverse problem.
, so we just need to convert between the two. This is known as the inverse problem. .
.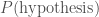 is the prior, because it’s what we believed about our hypothesis before we got the data, and
is the prior, because it’s what we believed about our hypothesis before we got the data, and  is the evidence. If ever you hear of someone doing something in a Bayesian way, it just means they are using the formula above. I think it’s rather silly to point this out, as it’s really the only logical way to do science, but people like to put “Bayesian” in the
is the evidence. If ever you hear of someone doing something in a Bayesian way, it just means they are using the formula above. I think it’s rather silly to point this out, as it’s really the only logical way to do science, but people like to put “Bayesian” in the  .
. . The prior probability of not having the disease is
. The prior probability of not having the disease is  . The likelihood of our positive result is
. The likelihood of our positive result is  , which seems worrying. The evidence, the total probability of testing positive
, which seems worrying. The evidence, the total probability of testing positive 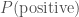 is found by adding the probability of a true positive and a false positive
is found by adding the probability of a true positive and a false positive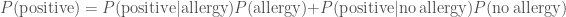 .
. . We thus have everything we need. Substituting everything in, gives
. We thus have everything we need. Substituting everything in, gives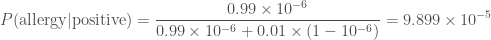 .
.
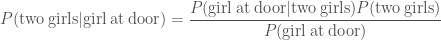 .
. . If we assume that it is equally likely that any one of the children opened the door, then the likelihood that one of the girls did so when their are two of them is
. If we assume that it is equally likely that any one of the children opened the door, then the likelihood that one of the girls did so when their are two of them is  . Similarly, if there were two boys, the probability of a girl answering the door is
. Similarly, if there were two boys, the probability of a girl answering the door is  . The evidence, the total probability of a girl being at the door is
. The evidence, the total probability of a girl being at the door is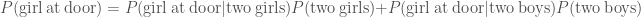 .
. .
. .
. , makes a difference. We know the probability of surviving the fatal dose is
, makes a difference. We know the probability of surviving the fatal dose is 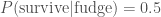 . The evidence, the total probability of surviving
. The evidence, the total probability of surviving  , is calculated by considering the two possible sequence of events: either Ted ate the fudge and survived or he didn’t eat the fudge and survived
, is calculated by considering the two possible sequence of events: either Ted ate the fudge and survived or he didn’t eat the fudge and survived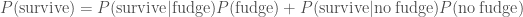 .
. . Since Ted either ate the fudge or he didn’t
. Since Ted either ate the fudge or he didn’t 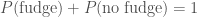 . Therefore,
. Therefore,![P(\mathrm{survive}) = 0.5 P(\mathrm{fudge}) + [1 - P(\mathrm{fudge})] = 1 - 0.5 P(\mathrm{fudge})](https://s0.wp.com/latex.php?latex=P%28%5Cmathrm%7Bsurvive%7D%29+%3D+0.5+P%28%5Cmathrm%7Bfudge%7D%29+%2B+%5B1+-+P%28%5Cmathrm%7Bfudge%7D%29%5D+%3D+1+-+0.5+P%28%5Cmathrm%7Bfudge%7D%29&bg=ffffff&fg=444444&s=0&c=20201002) .
. .
. . In this case,
. In this case, .
. . In this case we are in a state of ignorance. Our posterior is
. In this case we are in a state of ignorance. Our posterior is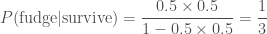 .
. .
. . Then
. Then .
.
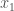 ,
, 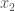 , etc., or as
, etc., or as  where the subscript
where the subscript  is used as shorthand to indicate any of the possible outcomes. The probability of the numeric value being a particular
is used as shorthand to indicate any of the possible outcomes. The probability of the numeric value being a particular  . For rolling our dice, the outcomes are one to six (
. For rolling our dice, the outcomes are one to six ( ,
,  , etc.) and the probabilities are
, etc.) and the probabilities are .
.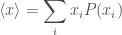 ,
, means
means 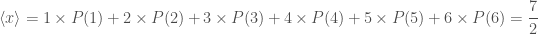 .
.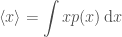 ,
,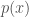 is the probability density function.
is the probability density function.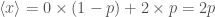 ,
, is less than one, so if
is less than one, so if  , it’s worth playing. If we were tossing a (fair) coin, we’d expect to come out even, if we had to roll a six, we’d expect to pay more.
, it’s worth playing. If we were tossing a (fair) coin, we’d expect to come out even, if we had to roll a six, we’d expect to pay more. . Imagine each outcome
. Imagine each outcome  times, then the mean is
times, then the mean is .
. so that
so that  .
. . This can be done by adding up probabilities until you get a half
. This can be done by adding up probabilities until you get a half .
. ,
,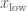 is the lower limit of the distribution. (That’s all the calculus out of the way now, so if you’re not a fan you can relax). The
is the lower limit of the distribution. (That’s all the calculus out of the way now, so if you’re not a fan you can relax). The  .
. .
.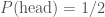 , or if rolling a die, the probability of getting a six is
, or if rolling a die, the probability of getting a six is  .
. is given by the
is given by the  .
. that was larger than zero, but smaller than the fatal dose
that was larger than zero, but smaller than the fatal dose  . If we a had probability density function
. If we a had probability density function  , we would calculate
, we would calculate .
.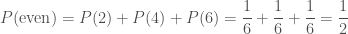 .
. is in each infinitesimal range
is in each infinitesimal range  ).
). .
. .
. is the probability of
is the probability of  given that
given that 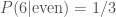 . If I told you that I have rolled a six, then the probability of me having rolled an even number is
. If I told you that I have rolled a six, then the probability of me having rolled an even number is  —it’s a dead cert, so bet all your fudge on that! When combining probabilities from dependent events, we chain probabilities together in a logical chain. The probability of rolling a six and an even number is the probability of rolling an even number multiplied by the probability of rolling a six given that I rolled an even number
—it’s a dead cert, so bet all your fudge on that! When combining probabilities from dependent events, we chain probabilities together in a logical chain. The probability of rolling a six and an even number is the probability of rolling an even number multiplied by the probability of rolling a six given that I rolled an even number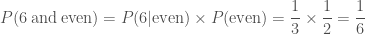 ,
,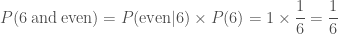 .
. .
. .
. .
. .
.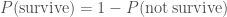 .
.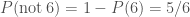 . The probability of not surviving is much easier to work out as there’s only one way that can happen: rolling a six and then overdosing on fudge. The probability is
. The probability of not surviving is much easier to work out as there’s only one way that can happen: rolling a six and then overdosing on fudge. The probability is ,
,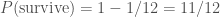 , exactly as before, but in fewer steps.
, exactly as before, but in fewer steps.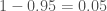 , or one in twenty. The probability of rolling two sixes is
, or one in twenty. The probability of rolling two sixes is  or about one in forty. Hence, you should be almost twice as surprised by rolling double six as for a 95% confidence-level result being incorrect.
or about one in forty. Hence, you should be almost twice as surprised by rolling double six as for a 95% confidence-level result being incorrect.