Probabilities and science
Understanding probabilities is important in science. Once you’ve done an experiment, you need to be able to extract from your data information about your theory. Only rarely do you get a simple yes or no: most of the time you have to work with probabilities to quantify your degree of certainty. I’ll (probably) be writing about probabilities in connection with my research, so I thought it would be useful to introduce some of the concepts.
I’ll be writing a series of posts, hopefully going through from the basics to the limits of my understanding. We’ll begin with introducing the concept of probability. There’s a little bit of calculus, but you can skip that without effecting the rest, just remember you can’t grow up to be big and strong if you don’t finish your calculus.
What is a probability?
A probability describes the degree of belief that you have in a proposition. We talk about probabilities quite intuitively: there are some angry-looking, dark clouds overhead and I’ve just lit the barbecue, so it’s probably going to rain; it’s more likely that United will win this year’s sportsball league than Rovers, or it’s more credible that Ted is exaggerating in his anecdote than he actually ate that much fudge…
We formalise the concept of a probability, so that it can be used in calculations, by assigning them numerical values (not by making them wear a bow-tie, although that is obviously cool). Conventionally, we use 0 for impossible, 1 for certain and the range in between for intermediate probabilities. For example, if we were tossing a coin, we might expect it to be heads half the time, hence the probability of heads is 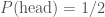

For both the coin and the die we have a number of equally probable outcomes: two for the coin (heads and tails) and six for the die (1, 2, 3, 4, 5 and 6). This does not have to be the case: imagine picking a letter at random from a sample of English text. Some letters are more common than others—this is why different letters have different values in Scrabble and why hangman can be tricky. The most frequent letter is “e”, the probability of picking it is about 0.12, and the least frequent is “z”, the probability of picking that is just 0.0007.
Often we consider a parameter that has a continuous range, rather than discrete values (as in the previous examples). For example, I might be interested in the mass of a black hole, which can have any positive value. We then use a probability density function 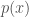


Performing an integral is just calculating the area under a curve, it can be thought of a the equivalent of adding up an infinite number of infinitely closely spaced slices. Returning to how much fudge Ted actually ate, we might to find the probability that he a mass of fudge 



The probability density is largest where the probability is greatest and smallest where the probability is smallest, as you’d expect. Calculating probabilities and probability distributions is, in general, a difficult problem, it’s actually what I spend a lot of my time doing. We’ll return to calculating probabilities later.
Combining probabilities
There are several recipes for combining probabilities to construct other probabilities, just like there are recipes to combine sugar and dairy to make fudge. Admittedly, probabilities are less delicious than fudge, but they are also less likely to give you cavities. If we have a set of of disjoint outcomes, we can work out the probability of that set by adding up the probabilities of the individual outcomes. For example, when rolling our die, the probability of getting an even number is
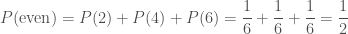
(This is similar to what we’re doing when integrating up the probability density function for continuous distributions: there we’re adding up the probability that the variable 

If we have two independent events, then the probability of both of them occurring is calculated by multiplying the two individual probabilities together. For example, we could consider the probability of rolling a six and the probability of Ted surviving eating the lethal dose of fudge, then

The most commonly quoted quantity for a lethal dose is the median lethal dose or LD50, which is the dose that kills half the population, so we can take the probability of surviving to be 0.5. Thus,

Events are independent if they don’t influence each other. Rolling a six shouldn’t influence Ted’s medical condition, and Ted’s survival shouldn’t influence the roll of a die, so these events are independent.
Things are more interesting when events are not independent. We then have to deal with conditional probabilities: the conditional probability 


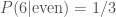

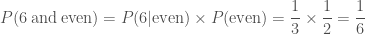
or equivalently the probability of rolling six multplied by the probability of rolling an even number given that I rolled a six
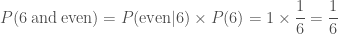
Reassuringly, we do get the same answer. This is a bit of a silly example, as we know that if we’ve rolled a six we have rolled an even number, so all we are doing if calculating the probability of rolling a six.
We can use conditional probabilities for independent events: this is really easy as the conditional probability is just the straight probability. The probability of Ted surviving his surfeit of fudge given that I rolled a six is just the probability of him surviving, 
Let’s try a more complicated example, let’s imagine that Ted is playing fudge roulette. This is like Russian roulette, except you roll a die and if it comes up six, then you have to eat the lethal dose of fudge. His survival probability now depends on the roll of the die. We want to calculate the probability that Ted will live to tomorrow. If Ted doesn’t roll a six, we’ll assume that he has a 100% survive rate (based on that one anecdote where he claims to have created a philosopher’s stone by soaking duct tape in holy water), this isn’t quite right, but is good enough. The probability of Ted surviving given he didn’t roll a six is

The probability of Ted rolling a six (and eating the fudge) and then surviving is

We have two disjoint outcomes (rolling a six and survivng, and not rolling a six and surving), so the total probability of surviving is given by the sum

It seems likely that he’ll make it, although fudge roulette is still a dangerous game!
There’s actually an easier way of calculating the probability that Ted survives. There are only two possible outcomes: Ted survives or he doesn’t. Since one of these must happen, their probabilities must add to one: the survive probability is
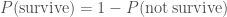
We’ve already seen this, as we’ve used the probability of not rolling a six is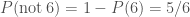

and so the survival probability is 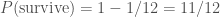
In a future post we’ll try working out the probability that Ted did eat a lethal dose of fudge given that he is alive to tell the anecdote. This is known as an inverse problem, and is similar to what scientists do all the time. We do experiments and get data, then we need to work out the probability of our theory (that Ted ate the fudge) being correct given the data (that he’s still alive).
Interpreting probabilities
We have now discussed what a probability is and how we can combine them. We should now think about how to interpret them. It’s easy enough to understand that a probability of 0.05 means that we expect something should happen on average once in 20 times, and that it is more probable than something with a probability of 0.01, but less likely than something with a probability of 0.10. However, we are not good at having an intuitive understanding of probabilities.
Consider the case that a scientist announces a result with 95% confidence. That sounds pretty good. Think how surprised you would be (assuming that their statistics are all correct) that the result was wrong. I feel like I would be pretty surprised. Now consider rolling tow dice, how surprised would you be if you rolled two sixes? The probability of the result being wrong is 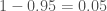

When dealing with probabilities, I find it useful to make a comparison to something familiar. While Ted is more likely than not to survive fudge roulette, there is a one is twelve chance of dying. That’s three times as likely as rolling a double six, or equally probable as rolling a six and getting heads. That’s riskier than I’d like, so I’m going to stick to consuming fudge in moderation.
