Gravitational-wave astronomy lets us observing binary black holes. These systems, being made up of two black holes, are pretty difficult to study by any other means. It has long been argued that with this new information we can unravel the mysteries of stellar evolution. Just as a palaeontologist can discover how long-dead animals lived from their bones, we can discover how massive stars lived by studying their black hole remnants. In this paper, we quantify how much we can really learn from this black hole palaeontology—after 1000 detections, we should pin down some of the most uncertain parameters in binary evolution to a few percent precision.
Life as a binary
There are many proposed ways of making a binary black hole. The current leading contender is isolated binary evolution: start with a binary star system (most stars are in binaries or higher multiples, our lonesome Sun is a little unusual), and let the stars evolve together. Only a fraction will end with black holes close enough to merge within the age of the Universe, but these would be the sources of the signals we see with LIGO and Virgo. We consider this isolated binary scenario in this work [bonus note].
Now, you might think that with stars being so fundamentally important to astronomy, and with binary stars being so common, we’d have the evolution of binaries figured out by now. It turns out it’s actually pretty messy, so there’s lots of work to do. We consider constraining four parameters which describe the bits of binary physics which we are currently most uncertain of:
- Black hole natal kicks—the push black holes receive when they are born in supernova explosions. We now the neutron stars get kicks, but we’re less certain for black holes [bonus note].
- Common envelope efficiency—one of the most intricate bits of physics about binaries is how mass is transferred between stars. As they start exhausting their nuclear fuel they puff up, so material from the outer envelope of one star may be stripped onto the other. In the most extreme cases, a common envelope may form, where so much mass is piled onto the companion, that both stars live in a single fluffy envelope. Orbiting inside the envelope helps drag the two stars closer together, bringing them closer to merging. The efficiency determines how quickly the envelope becomes unbound, ending this phase.
- Mass loss rates during the Wolf–Rayet (not to be confused with Wolf 359) and luminous blue variable phases–stars lose mass through out their lives, but we’re not sure how much. For stars like our Sun, mass loss is low, there is enough to gives us the aurora, but it doesn’t affect the Sun much. For bigger and hotter stars, mass loss can be significant. We consider two evolutionary phases of massive stars where mass loss is high, and currently poorly known. Mass could be lost in clumps, rather than a smooth stream, making it difficult to measure or simulate.
We use parameters describing potential variations in these properties are ingredients to the COMPAS population synthesis code. This rapidly (albeit approximately) evolves a population of stellar binaries to calculate which will produce merging binary black holes.
The question is now which parameters affect our gravitational-wave measurements, and how accurately we can measure those which do?

Binary black hole merger rate at three different redshifts 
Gravitational-wave observations
For our deductions, we use two pieces of information we will get from LIGO and Virgo observations: the total number of detections, and the distributions of chirp masses. The chirp mass is a combination of the two black hole masses that is often well measured—it is the most important quantity for controlling the inspiral, so it is well measured for low mass binaries which have a long inspiral, but is less well measured for higher mass systems. In reality we’ll have much more information, so these results should be the minimum we can actually do.
We consider the population after 1000 detections. That sounds like a lot, but we should have collected this many detections after just 2 or 3 years observing at design sensitivity. Our default COMPAS model predicts 484 detections per year of observing time! Honestly, I’m a little scared about having this many signals…
For a set of population parameters (black hole natal kick, common envelope efficiency, luminous blue variable mass loss and Wolf–Rayet mass loss), COMPAS predicts the number of detections and the fraction of detections as a function of chirp mass. Using these, we can work out the probability of getting the observed number of detections and fraction of detections within different chirp mass ranges. This is the likelihood function: if a given model is correct we are more likely to get results similar to its predictions than further away, although we expect their to be some scatter.
If you like equations, the from of our likelihood is explained in this bonus note. If you don’t like equations, there’s one lurking in the paragraph below. Just remember, that it can’t see you if you don’t move. It’s OK to skip the equation.
To determine how sensitive we are to each of the population parameters, we see how the likelihood changes as we vary these. The more the likelihood changes, the easier it should be to measure that parameter. We wrap this up in terms of the Fisher information matrix. This is defined as

where 
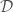
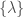
We simulated several populations of binary black hole signals, and then calculate measurement uncertainties for our four population uncertainties to see what we could learn from these measurements.
Results
Using just the rate information, we find that we can constrain a combination of the common envelope efficiency and the Wolf–Rayet mass loss rate. Increasing the common envelope efficiency ends the common envelope phase earlier, leaving the binary further apart. Wider binaries take longer to merge, so this reduces the merger rate. Similarly, increasing the Wolf–Rayet mass loss rate leads to wider binaries and smaller black holes, which take longer to merge through gravitational-wave emission. Since the two parameters have similar effects, they are anticorrelated. We can increase one and still get the same number of detections if we decrease the other. There’s a hint of a similar correlation between the common envelope efficiency and the luminous blue variable mass loss rate too, but it’s not quite significant enough for us to be certain it’s there.

Fisher information matrix estimates for fractional measurement precision of the four population parameters: the black hole natal kick 

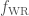
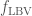
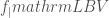
Adding in the chirp mass distribution gives us more information, and improves our measurement accuracies. The fraction uncertainties are about 2% for the two mass loss rates and the common envelope efficiency, and about 5% for the black hole natal kick. We’re less sensitive to the natal kick because the most massive black holes don’t receive a kick, and so are unaffected by the kick distribution [bonus note]. In any case, these measurements are exciting! With this type of precision, we’ll really be able to learn something about the details of binary evolution.

Measurement precision for the four population parameters after 1000 detections. We quantify the precision with the standard deviation estimated from the Fisher inforamtion matrix. We show results from 1500 realisations of the population to give an idea of scatter. Figure 5 of Barrett et al. (2018)
The accuracy of our measurements will improve (on average) with the square root of the number of gravitational-wave detections. So we can expect 1% measurements after about 4000 observations. However, we might be able to get even more improvement by combining constraints from other types of observation. Combining different types of observation can help break degeneracies. I’m looking forward to building a concordance model of binary evolution, and figuring out exactly how massive stars live their lives.
arXiv: 1711.06287 [astro-ph.HE]
Journal: Monthly Notices of the Royal Astronomical Society; 477(4):4685–4695; 2018
Favourite dinosaur: Professor Science
Bonus notes
Channel selection
In practise, we will need to worry about how binary black holes are formed, via isolated evolution or otherwise, before inferring the parameters describing binary evolution. This makes the problem more complicated. Some parameters, like mass loss rates or black hole natal kicks, might be common across multiple channels, while others are not. There are a number of ways we might be able to tell different formation mechanisms apart, such as by using spin measurements.
Kick distribution
We model the supernova kicks 

where 

where 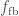
The likelihood
In this analysis, we have two pieces of information: the number of detections, and the chirp masses of the detections. The first is easy to summarise with a single number. The second is more complicated, and we consider the fraction of events within different chirp mass bins.
Our COMPAS model predicts the merger rate 

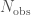


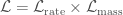
For the rate likelihood, we need the probability of observing
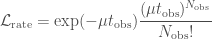
where 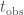
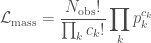
These look a little messy, but they simplify when you take the logarithm, as we need to do for the Fisher information matrix.
When we substitute in our likelihood into the expression for the Fisher information matrix, we get
![\displaystyle F_{ij} = \mu t_\mathrm{obs} \left[ \frac{1}{\mu^2} \frac{\partial \mu}{\partial \lambda_i} \frac{\partial \mu}{\partial \lambda_j} + \sum_k\frac{1}{p_k} \frac{\partial p_k}{\partial \lambda_i} \frac{\partial p_k}{\partial \lambda_j} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+F_%7Bij%7D+%3D+%5Cmu+t_%5Cmathrm%7Bobs%7D+%5Cleft%5B+%5Cfrac%7B1%7D%7B%5Cmu%5E2%7D+%5Cfrac%7B%5Cpartial+%5Cmu%7D%7B%5Cpartial+%5Clambda_i%7D%C2%A0%5Cfrac%7B%5Cpartial+%5Cmu%7D%7B%5Cpartial+%5Clambda_j%7D%C2%A0+%2B+%5Csum_k%5Cfrac%7B1%7D%7Bp_k%7D+%5Cfrac%7B%5Cpartial+p_k%7D%7B%5Cpartial+%5Clambda_i%7D%C2%A0%5Cfrac%7B%5Cpartial+p_k%7D%7B%5Cpartial+%5Clambda_j%7D+%5Cright%5D&bg=ffffff&fg=444444&s=0&c=20201002)
Conveniently, although we only need to evaluate first-order derivatives, even though the Fisher information matrix is defined in terms of second derivatives. The expected number of events is 

For anyone worrying about using the likelihood rather than the posterior for these estimates, the high number of detections [bonus note] should mean that the information we’ve gained from the data overwhelms our prior, meaning that the shape of the posterior is dictated by the shape of the likelihood.
Interpretation of the Fisher information matrix
As an alternative way of looking at the Fisher information matrix, we can consider the shape of the likelihood close to its peak. Around the maximum likelihood point, the first-order derivatives of the likelihood with respect to the population parameters is zero (otherwise it wouldn’t be the maximum). The maximum likelihood values of 

So long as we are working close to the maximum likelihood point, we can approximate the distribution as a multidimensional normal distribution with its covariance matrix determined by the inverse of the Fisher information matrix. Our results for the measurement uncertainties are made subject to this approximation (which we did check was OK).
Approximating the likelihood this way should be safe in the limit of large 
Michele Vallisneri has a good paper looking at using the Fisher information matrix for gravitational wave parameter estimation (rather than our problem of binary population synthesis). There is a good discussion of its range of validity. The high signal-to-noise ratio limit for gravitational wave signals corresponds to our high number of detections limit.




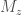 . Results are shown for the different astrophysical models, and for the different signal models. The astrophysical model has little impact on the uncertainties. M4 shows a slight difference as it assumes heavier stellar-mass black holes. The results with the two signal models agree when the massive black hole is not spinning (M10 and M11). Otherwise, measurements are more precise with the AKK signal model, as this includes extra signal from the end of the inspiral. Part of Figure 11 of
. Results are shown for the different astrophysical models, and for the different signal models. The astrophysical model has little impact on the uncertainties. M4 shows a slight difference as it assumes heavier stellar-mass black holes. The results with the two signal models agree when the massive black hole is not spinning (M10 and M11). Otherwise, measurements are more precise with the AKK signal model, as this includes extra signal from the end of the inspiral. Part of Figure 11 of 
 . The results mirror those for the masses above. Part of Figure 11 of
. The results mirror those for the masses above. Part of Figure 11 of  where
where  is the frequency emitted, and
is the frequency emitted, and 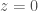 for a nearby source, and is larger for further away sources). Lower frequency gravitational waves correspond to higher mass systems, so it is often convenient to work with the redshifted mass, the mass corresponding to the signal you measure if you ignore redshifting. The redshifted mass of the massive black hole is
for a nearby source, and is larger for further away sources). Lower frequency gravitational waves correspond to higher mass systems, so it is often convenient to work with the redshifted mass, the mass corresponding to the signal you measure if you ignore redshifting. The redshifted mass of the massive black hole is  where
where  is the true mass. To work out the true mass, we need the redshift, which means we need to measure the distance to the source.
is the true mass. To work out the true mass, we need the redshift, which means we need to measure the distance to the source.
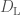 . The signal model is not as important here, as the uncertainty only depends on how loud the signal is. Part of Figure 12 of
. The signal model is not as important here, as the uncertainty only depends on how loud the signal is. Part of Figure 12 of 
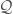 . Results are similar to the mass and spin measurements. Figure 13 of
. Results are similar to the mass and spin measurements. Figure 13 of 

 . The true location is marked by the cross. Leo poetically described this as looking like the seeds of the
. The true location is marked by the cross. Leo poetically described this as looking like the seeds of the  can be approximated using an ansatz
can be approximated using an ansatz![\displaystyle p(D|\mathrm{data}) \propto D^2\exp\left[-\frac{(D - \mu)^2}{2\sigma}\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+p%28D%7C%5Cmathrm%7Bdata%7D%29+%5Cpropto+D%5E2%5Cexp%5Cleft%5B-%5Cfrac%7B%28D+-+%5Cmu%29%5E2%7D%7B2%5Csigma%7D%5Cright%5D&bg=ffffff&fg=444444&s=0&c=20201002) ,
, are calculated for each pixel individually. The form of this ansatz can be understood as the
are calculated for each pixel individually. The form of this ansatz can be understood as the  , and the likelihood can often be well approximated as a Gaussian distribution, which gives the other piece [
, and the likelihood can often be well approximated as a Gaussian distribution, which gives the other piece [