The full results of our second advanced-detector observing run (O2) have now been released—we’re pleased to announce four new gravitational wave signals: GW170729, GW170809, GW170818 and GW170823 [bonus note]. These latest observations are all of binary black hole systems. Together, they bring our total to 10 observations of binary black holes, and 1 of a binary neutron star. With more frequent detections on the horizon with our third observing run due to start early 2019, the era of gravitational wave astronomy is truly here.

The population of black holes and neutron stars observed with gravitational waves and with electromagnetic astronomy. You can play with an interactive version of this plot online.
The new detections are largely consistent with our previous findings. GW170809, GW170818 and GW170823 are all similar to our first detection GW150914. Their black holes have masses around 20 to 40 times the mass of our Sun. I would lump GW170104 and GW170814 into this class too. Although there were models that predicted black holes of these masses, we weren’t sure they existed until our gravitational wave observations. The family of black holes continues out of this range. GW151012, GW151226 and GW170608 fall on the lower mass side. These overlap with the population of black holes previously observed in X-ray binaries. Lower mass systems can’t be detected as far away, so we find fewer of these. On the higher end we have GW170729 [bonus note]. Its source is made up of black holes with masses 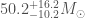
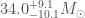


Of the new detections, GW170729, GW170809 and GW170818 were both observed by the Virgo detector as well as the two LIGO detectors. Virgo joined O2 for an exciting August [bonus note], and we decided that the data at the time of GW170729 were good enough to use too. Unfortunately, Virgo wasn’t observing at the time of GW170823. GW170729 and GW170809 are very quiet in Virgo, you can’t confidently say there is a signal there [bonus note]. However, GW170818 is a clear detection like GW170814. Well done Virgo!
Using the collection of results, we can start understand the physics of these binary systems. We will be summarising our findings in a series of papers. A huge amount of work went into these.
The papers
The O2 Catalogue Paper
Title: GWTC-1: A gravitational-wave transient catalog of compact binary mergers observed by LIGO and Virgo during the first and second observing runs
arXiv: 1811.12907 [astro-ph.HE]
Data: Catalogue; Parameter estimation results
Journal: Physical Review X; 9(3):031040(49); 2019
LIGO science summary: GWTC-1: A new catalog of gravitational-wave detections
The paper summarises all our observations of binaries to date. It covers our first and second observing runs (O1 and O2). This is the paper to start with if you want any information. It contains estimates of parameters for all our sources, including updates for previous events. It also contains merger rate estimates for binary neutron stars and binary black holes, and an upper limit for neutron star–black hole binaries. We’re still missing a neutron star–black hole detection to complete the set.
More details: The O2 Catalogue Paper
The O2 Populations Paper
Title: Binary black hole population properties inferred from the first and second observing runs of Advanced LIGO and Advanced Virgo
arXiv: 1811.12940 [astro-ph.HE]
Journal: Astrophysical Journal Letters; 882(2):L24(30); 2019
Data: Population inference results
LIGO science summary: Binary black hole properties inferred from O1 and O2
Using our set of ten binary black holes, we can start to make some statistical statements about the population: the distribution of masses, the distribution of spins, the distribution of mergers over cosmic time. With only ten observations, we still have a lot of uncertainty, and can’t make too many definite statements. However, if you were wondering why we don’t see any more black holes more massive than GW170729, even though we can see these out to significant distances, so are we. We infer that almost all stellar-mass black holes have masses less than 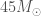
More details: The O2 Populations Paper
The O2 Catalogue Paper
Synopsis: O2 Catalogue Paper
Read this if: You want the most up-to-date gravitational results
Favourite part: It’s out! We can tell everyone about our FOUR new detections
This is a BIG paper. It covers our first two observing runs and our main searches for coalescing stellar mass binaries. There will be separate papers going into more detail on searches for other gravitational wave signals.
The instruments
Gravitational wave detectors are complicated machines. You don’t just take them out of the box and press go. We’ll be slowly improving the sensitivity of our detectors as we commission them over the next few years. O2 marks the best sensitivity achieved to date. The paper gives a brief overview of the detector configurations in O2 for both LIGO detectors, which did differ, and Virgo.
During O2, we realised that one source of noise was beam jitter, disturbances in the shape of the laser beam. This was particularly notable in Hanford, where there was a spot on the one of the optics. Fortunately, we are able to measure the effects of this, and hence subtract out this noise. This has now been done for the whole of O2. It makes a big difference! Derek Davis and TJ Massinger won the first LIGO Laboratory Award for Excellence in Detector Characterization and Calibration™ for implementing this noise subtraction scheme (the award citation almost spilled the beans on our new detections). I’m happy that GW170104 now has an increased signal-to-noise ratio, which means smaller uncertainties on its parameters.
The searches
We use three search algorithms in this paper. We have two matched-filter searches (GstLAL and PyCBC). These compare a bank of templates to the data to look for matches. We also use coherent WaveBurst (cWB), which is a search for generic short signals, but here has been tuned to find the characteristic chirp of a binary. Since cWB is more flexible in the signals it can find, it’s slightly less sensitive than the matched-filter searches, but it gives us confidence that we’re not missing things.
The two matched-filter searches both identify all 11 signals with the exception of GW170818, which is only found by GstLAL. This is because PyCBC only flags signals above a threshold in each detector. We’re confident it’s real though, as it is seen in all three detectors, albeit below PyCBC’s threshold in Hanford and Virgo. (PyCBC only looked at signals found in coincident Livingston and Hanford in O2, I suspect they would have found it if they were looking at all three detectors, as that would have let them lower their threshold).
The search pipelines try to distinguish between signal-like features in the data and noise fluctuations. Having multiple detectors is a big help here, although we still need to be careful in checking for correlated noise sources. The background of noise falls off quickly, so there’s a rapid transition between almost-certainly noise to almost-certainly signal. Most of the signals are off the charts in terms of significance, with GW170818, GW151012 and GW170729 being the least significant. GW170729 is found with best significance by cWB, that gives reports a false alarm rate of 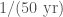

Cumulative histogram of results from GstLAL (top left), PyCBC (top right) and cWB (bottom). The expected background is shown as the dashed line and the shaded regions give Poisson uncertainties. The search results are shown as the solid red line and named gravitational-wave detections are shown as blue dots. More significant results are further to the right of the plot. Fig. 2 and Fig. 3 of the O2 Catalogue Paper.
The false alarm rate indicates how often you would expect to find something at least as signal like if you were to analyse a stretch of data with the same statistical properties as the data considered, assuming that they is only noise in the data. The false alarm rate does not fold in the probability that there are real gravitational waves occurring at some average rate. Therefore, we need to do an extra layer of inference to work out the probability that something flagged by a search pipeline is a real signal versus is noise.
The results of this calculation is given in Table IV. GW170729 has a 94% probability of being real using the cWB results, 98% using the GstLAL results, but only 52% according to PyCBC. Therefore, if you’re feeling bold, you might, say, only wager the entire economy of the UK on it being real.
We also list the most marginal triggers. These all have probabilities way below being 50% of being real: if you were to add them all up you wouldn’t get a total of 1 real event. (In my professional opinion, they are garbage). However, if you want to check for what we might have missed, these may be a place to start. Some of these can be explained away as instrumental noise, say scattered light. Others show no obvious signs of disturbance, so are probably just some noise fluctuation.
The source properties
We give updated parameter estimates for all 11 sources. These use updated estimates of calibration uncertainty (which doesn’t make too much difference), improved estimate of the noise spectrum (which makes some difference to the less well measured parameters like the mass ratio), the cleaned data (which helps for GW170104), and our most currently complete waveform models [bonus note].
This plot shows the masses of the two binary components (you can just make out GW170817 down in the corner). We use the convention that the more massive of the two is 
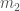

Estimated masses for the two binary objects for each of the events in O1 and O2. From lowest chirp mass (left; red) to highest (right; purple): GW170817 (solid), GW170608 (dashed), GW151226 (solid), GW151012 (dashed), GW170104 (solid), GW170814 (dashed), GW170809 (dashed), GW170818 (dashed), GW150914 (solid), GW170823 (dashed), GW170729 (solid). The contours mark the 90% credible regions. The grey area is excluded from our convention on masses. Part of Fig. 4 of the O2 Catalogue Paper. The mass ratio is 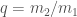
As well as mass, black holes have a spin. For the final black hole formed in the merger, these spins are always around 0.7, with a little more or less depending upon which way the spins of the two initial black holes were pointing. As well as being probably the most most massive, GW170729’s could have the highest final spin! It is a record breaker. It radiated a colossal 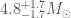

Estimated final masses and spins for each of the binary black hole events in O1 and O2. From lowest chirp mass (left; red–orange) to highest (right; purple): GW170608 (dashed), GW151226 (solid), GW151012 (dashed), GW170104 (solid), GW170814 (dashed), GW170809 (dashed), GW170818 (dashed), GW150914 (solid), GW170823 (dashed), GW170729 (solid). The contours mark the 90% credible regions. Part of Fig. 4 of the O2 Catalogue Paper.
There is considerable uncertainty on the spins as there are hard to measure. The best combination to pin down is the effective inspiral spin parameter 
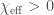

Estimated effective inspiral spin parameters for each of the events in O1 and O2. From lowest chirp mass (left; red) to highest (right; purple): GW170817, GW170608, GW151226, GW151012, GW170104, GW170814, GW170809, GW170818, GW150914, GW170823, GW170729. Part of Fig. 5 of the O2 Catalogue Paper.
For our analysis, we use two different waveform models to check for potential sources of systematic error. They agree pretty well. The spins are where they show most difference (which makes sense, as this is where they differ in terms of formulation). For GW151226, the effective precession waveform IMRPhenomPv2 gives 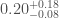
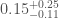
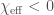
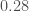
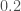
Our measurement of 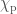

Estimated effective inspiral spin parameters for each of the events in O1 and O2. From lowest chirp mass (left; red) to highest (right; purple): GW170817, GW170608, GW151226, GW151012, GW170104, GW170814, GW170809, GW170818, GW150914, GW170823, GW170729. The left (coloured) part of the plot shows the posterior distribution; the right (white) shows the prior conditioned by the effective inspiral spin parameter constraints. Part of Fig. 5 of the O2 Catalogue Paper.
One final measurement which we can make (albeit with considerable uncertainty) is the distance to the source. The distance influences how loud the signal is (the further away, the quieter it is). This also depends upon the inclination of the source (a binary edge-on is quieter than a binary face-on/off). Therefore, the distance is correlated with the inclination and we end up with some butterfly-like plots. GW170729 is again a record setter. It comes from a luminosity distance of 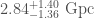
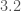
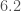

Estimated luminosity distances and orbital inclinations for each of the events in O1 and O2. From lowest chirp mass (left; red) to highest (right; purple): GW170817 (solid), GW170608 (dashed), GW151226 (solid), GW151012 (dashed), GW170104 (solid), GW170814 (dashed), GW170809 (dashed), GW170818 (dashed), GW150914 (solid), GW170823 (dashed), GW170729 (solid). The contours mark the 90% credible regions.An inclination of zero means that we’re looking face-on along the direction of the total angular momentum, and inclination of 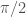
Waveform reconstructions
To check our results, we reconstruct the waveforms from the data to see that they match our expectations for binary black hole waveforms (and there’s not anything extra there). To do this, we use unmodelled analyses which assume that there is a coherent signal in the detectors: we use both cWB and BayesWave. The results agree pretty well. The reconstructions beautifully match our templates when the signal is loud, but, as you might expect, can resolve the quieter details. You’ll also notice the reconstructions sometimes pick up a bit of background noise away from the signal. This gives you and idea of potential fluctuations.

Time–frequency maps and reconstructed signal waveforms for the binary black holes. For each event we show the results from the detector where the signal was loudest. The left panel for each shows the time–frequency spectrogram with the upward-sweeping chip. The right show waveforms: blue the modelled waveforms used to infer parameters (LALInf; top panel); the red wavelet reconstructions (BayesWave; top panel); the black is the maximum-likelihood cWB reconstruction (bottom panel), and the green (bottom panel) shows reconstructions for simulated similar signals. I think the agreement is pretty good! All the data have been whitened as this is how we perform the statistical analysis of our data. Fig. 10 of the O2 Catalogue Paper.
I still think GW170814 looks like a slug. Some people think they look like crocodiles.
We’ll be doing more tests of the consistency of our signals with general relativity in a future paper.
Merger rates
Given all our observations now, we can set better limits on the merger rates. Going from the number of detections seen to the number merger out in the Universe depends upon what you assume about the mass distribution of the sources. Therefore, we make a few different assumptions.
For binary black holes, we use (i) a power-law model for the more massive black hole similar to the initial mass function of stars, with a uniform distribution on the mass ratio, and (ii) use uniform-in-logarithmic distribution for both masses. These were designed to bracket the two extremes of potential distributions. With our observations, we’re starting to see that the true distribution is more like the power-law, so I expect we’ll be abandoning these soon. Taking the range of possible values from our calculations, the rate is in the range of 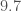

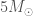
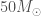
For binary neutron stars, which are perhaps more interesting astronomers, we use a uniform distribution of masses between 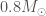
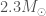


90% upper limits for neutron star–black hole binaries. Three black hole masses were tried and two spin distributions. Results are shown for the two matched-filter search algorithms. Fig. 14 of the O2 Catalogue Paper.
Finally, what about neutron star–black holes? Since we don’t have any detections, we can only place an upper limit. This is a maximum of 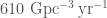
We are sure to discover lots more in O3… [bonus note].
The O2 Populations Paper
Synopsis: O2 Populations Paper
Read this if: You want the best family portrait of binary black holes
Favourite part: A maximum black hole mass?
Each detection is exciting. However, we can squeeze even more science out of our observations by looking at the entire population. Using all 10 of our binary black hole observations, we start to trace out the population of binary black holes. Since we still only have 10, we can’t yet be too definite in our conclusions. Our results give us some things to ponder, while we are waiting for the results of O3. I think now is a good time to start making some predictions.
We look at the distribution of black hole masses, black hole spins, and the redshift (cosmological time) of the mergers. The black hole masses tell us something about how you go from a massive star to a black hole. The spins tell us something about how the binaries form. The redshift tells us something about how these processes change as the Universe evolves. Ideally, we would look at these all together allowing for mixtures of binary black holes formed through different means. Given that we only have a few observations, we stick to a few simple models.
To work out the properties of the population, we perform a hierarchical analysis of our 10 binary black holes. We infer the properties of the individual systems, assuming that they come from a given population, and then see how well that population fits our data compared with a different distribution.
In doing this inference, we account for selection effects. Our detectors are not equally sensitive to all sources. For example, nearby sources produce louder signals and we can’t detect signals that are too far away, so if you didn’t account for this you’d conclude that binary black holes only merged in the nearby Universe. Perhaps less obvious is that we are not equally sensitive to all source masses. More massive binaries produce louder signals, so we can detect these further way than lighter binaries (up to the point where these binaries are so high mass that the signals are too low frequency for us to easily spot). This is why we detect more binary black holes than binary neutron stars, even though there are more binary neutron stars out here in the Universe.
Masses
When looking at masses, we try three models of increasing complexity:
- Model A is a simple power law for the mass of the more massive black hole
- Model B is the same power law, but we also allow the lower mass limit to vary from
instead of Model A’s
.
- Model C has the same power law, but now with some smoothing at the low-mass end, rather than a sharp turn-on. Additionally, it includes a Gaussian component towards higher masses. This was inspired by the possibility of pulsational pair-instability supernova causing a build up of black holes at certain masses: stars which undergo this lose extra mass, so you’d end up with lower mass black holes than if the stars hadn’t undergone the pulsations. The Gaussian could fit other effects too, for example if there was a secondary formation channel, or just reflect that the pure power law is a bad fit.
In allowing the mass distributions to vary, we find overall rates which match pretty well those we obtain with our main power-law rates calculation included in the O2 Catalogue Paper, higher than with the main uniform-in-log distribution.
The fitted mass distributions are shown in the plot below. The error bars are pretty broad, but I think the models agree on some broad features: there are more light black holes than heavy black holes; the minimum black hole mass is below about 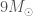
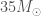

Binary black hole merger rate as a function of the primary mass (
That there does seem to be a drop off at higher masses is interesting. There could be something which stops stars forming black holes in this range. It has been proposed that there is a mass gap due to pair instability supernovae. These explosions completely disrupt their progenitor stars, leaving nothing behind. (I’m not sure if they are accompanied by a flash of green light). You’d expect this to kick for black holes of about 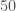

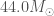
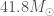
We can compare how well each of our three models fits the data by looking at their Bayes factors. These naturally incorporate the complexity of the models: models with more parameters (which can be more easily tweaked to match the data) are penalised so that you don’t need to worry about overfitting. We have a preference for Model C. It’s not strong, but I think good evidence that we can’t use a simple power law.
Spins
To model the spins:
- For the magnitude, we assume a beta distribution. There’s no reason for this, but these are convenient distributions for things between 0 and 1, which are the limits on black hole spin (0 is nonspinning, 1 is as fast as you can spin). We assume that both spins are drawn from the same distribution.
- For the spin orientations, we use a mix of an isotropic distribution and a Gaussian centred on being aligned with the orbital angular momentum. You’d expect an isotropic distribution if binaries were assembled dynamically, and perhaps something with spins generally aligned with each other if the binary evolved in isolation.
We don’t get any useful information on the mixture fraction. Looking at the spin magnitudes, we have a preference towards smaller spins, but still have support for large spins. The more misaligned spins are, the larger the spin magnitudes can be: for the isotropic distribution, we have support all the way up to maximal values.

Inferred spin magnitude distributions. The left shows results for the parametric distribution, assuming a mixture of almost aligned and isotropic spin, with the median (solid), 50% and 90% intervals shaded, and the posterior predictive distribution as the dashed line. Results are included both for beta distributions which can be singular at 0 and 1, and with these excluded. Model V is a very low spin model shown for comparison. The right shows a binned reconstruction of the distribution for aligned and isotropic distributions, showing the median and 90% intervals. Fig. 8 of the O2 Populations Paper.
Since spins are harder to measure than masses, it is not surprising that we can’t make strong statements yet. If we were to find something with definitely negative
Redshift evolution
As a simple model of evolution over cosmological time, we allow the merger rate to evolve as 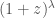
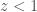

Evolution of the binary black hole merger rate (blue), showing median, 50% and 90% intervals. For comparison, a non-evolving rate calculated using Model B is shown too. Fig. 6 of the O2 Populations Paper.
We find that we prefer evolutions that increase with redshift. There’s an 88% probability that 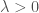
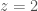
The local merger rate is broadly consistent with what we infer with our non-evolving distributions, but is a little on the lower side.
Bonus notes
Naming
Gravitational waves are named as GW-year-month-day, so our first observation from 14 September 2015 is GW150914. We realise that this convention suffers from a Y2K-style bug, but by the time we hit 2100, we’ll have so many detections we’ll need a new scheme anyway.
Previously, we had a second designation for less significant potential detections. They were LIGO–Virgo Triggers (LVT), the one example being LVT151012. No-one was really happy with this designation, but it stems from us being cautious with our first announcement, and not wishing to appear over bold with claiming we’d seen two gravitational waves when the second wasn’t that certain. Now we’re a bit more confident, and we’ve decided to simplify naming by labelling everything a GW on the understanding that this now includes more uncertain events. Under the old scheme, GW170729 would have been LVT170729. The idea is that the broader community can decide which events they want to consider as real for their own studies. The current condition for being called a GW is that the probability of it being a real astrophysical signal is at least 50%. Our 11 GWs are safely above that limit.
The naming change has hidden the fact that now when we used our improved search pipelines, the significance of GW151012 has increased. It would now be a GW even under the old scheme. Congratulations LVT151012, I always believed in you!

Is it of extraterrestrial origin, or is it just a blurry figure? GW151012: the truth is out there!.
Burning bright
We are lacking nicknames for our new events. They came in so fast that we kind of lost track. Ilya Mandel has suggested that GW170729 should be the Tiger, as it happened on the International Tiger Day. Since tigers are the biggest of the big cats, this seems apt.
Carl-Johan Haster argues that LIGO+tiger = Liger. Since ligers are even bigger than tigers, this seems like an excellent case to me! I’d vote for calling the bigger of the two progenitor black holes GW170729-tiger, the smaller GW170729-lion, and the final black hole GW17-729-liger.
Suggestions for other nicknames are welcome, leave your ideas in the comments.
August 2017—Something fishy or just Poisson statistics?
The final few weeks of O2 were exhausting. I was trying to write job applications at the time, and each time I sat down to work on my research proposal, my phone went off with another alert. You may be wondering about was special about August. Some have hypothesised that it is because Aaron Zimmerman, my partner for the analysis of GW170104, was on the Parameter Estimation rota to analyse the last few weeks of O2. The legend goes that Aaron is especially lucky as he was bitten by a radioactive Leprechaun. I can neither confirm nor deny this. However, I make a point of playing any lottery numbers suggested by him.
A slightly more mundane explanation is that August was when the detectors were running nice and stably. They were observing for a large fraction of the time. LIGO Livingston reached its best sensitivity at this time, although it was less happy for Hanford. We often quantify the sensitivity of our detectors using their binary neutron star range, the average distance they could see a binary neutron star system with a signal-to-noise ratio of 8. If this increases by a factor of 2, you can see twice as far, which means you survey 8 times the volume. This cubed factor means even small improvements can have a big impact. The LIGO Livingston range peak a little over 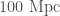
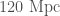

Binary neutron star range for the instruments across O2. The break around week 3 was for the holidays (We did work Christmas 2015). The break at week 23 was to tune-up the instruments, and clean the mirrors. At week 31 there was an earthquake in Montana, and the Hanford sensitivity didn’t recover by the end of the run. Part of Fig. 1 of the O2 Catalogue Paper.
Of course, in the case of GW170817, we just got lucky.
Sign errors
GW170809 was the first event we identified with Virgo after it joined observing. The signal in Virgo is very quiet. We actually got better results when we flipped the sign of the Virgo data. We were just starting to get paranoid when GW170814 came along and showed us that everything was set up right at Virgo. When I get some time, I’d like to investigate how often this type of confusion happens for quiet signals.
SEOBNRv3
One of the waveforms, which includes the most complete prescription of the precession of the spins of the black holes, we use in our analysis goes by the technical name of SEOBNRv3. It is extremely computationally expensive. Work has been done to improve that, but this hasn’t been implemented in our reviewed codes yet. We managed to complete an analysis for the GW170104 Discovery Paper, which was a huge effort. I said then to not expect it for all future events. We did it for all the black holes, even for the lowest mass sources which have the longest signals. I was responsible for GW151226 runs (as well as GW170104) and I started these back at the start of the summer. Eve Chase put in a heroic effort to get GW170608 results, we pulled out all the stops for that.
Thanksgiving
I have recently enjoyed my first Thanksgiving in the US. I was lucky enough to be hosted for dinner by Shane Larson and his family (and cats). I ate so much I thought I might collapse to a black hole. Apparently, a Thanksgiving dinner can be 3000–4500 calories. That sounds like a lot, but the merger of GW170729 would have emitted about 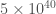
Confession
We cheated a little bit in calculating the rates. Roughly speaking, the merger rate is given by
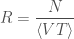
where 
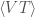


New sources
We saw our first binary black hole shortly after turning on the Advanced LIGO detectors. We saw our first binary neutron star shortly after turning on the Advanced Virgo detector. My money is therefore on our first neutron star–black hole binary shortly after we turn on the KAGRA detector. Because science…
 –
– , which is about
, which is about 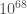 –
–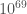
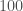 –
–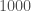 galaxies.
galaxies.


 is inversely proportional to the sixth power of the signal-to-noise ration
is inversely proportional to the sixth power of the signal-to-noise ration 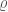 . This is what you would expect. The localization volume depends upon the angular uncertainty on the sky
. This is what you would expect. The localization volume depends upon the angular uncertainty on the sky  , the distance to the source
, the distance to the source  , and the distance uncertainty
, and the distance uncertainty  ,
, .
.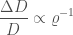 .
.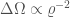 .
.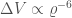 .
. , we want to know the probability that the parameters
, we want to know the probability that the parameters 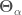 have different values, which is written as
have different values, which is written as  . This is calculated using
. This is calculated using ,
, is the likelihood, which we can calculate from our knowledge of the
is the likelihood, which we can calculate from our knowledge of the  is the prior on the parameters (what we would have guessed before we had the data), and the normalisation constant
is the prior on the parameters (what we would have guessed before we had the data), and the normalisation constant  is called the evidence. We’ll use the evidence again in the next layer of inference.
is called the evidence. We’ll use the evidence again in the next layer of inference. ,
,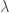 denotes which model we are considering.
denotes which model we are considering. , we can work this out using another application of Bayes’ theorem (yay)
, we can work this out using another application of Bayes’ theorem (yay) ,
, is just all the evidences for the individual events (given that model) multiplied together,
is just all the evidences for the individual events (given that model) multiplied together, 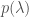 is our prior for the different models, and
is our prior for the different models, and 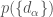 is another normalisation constant.
is another normalisation constant.
