GW150914 claimed the title of many firsts—it was the first direct observation of gravitational waves, the first observation of a binary black hole system, the first observation of two black holes merging, the first time time we’ve tested general relativity in such extreme conditions… However, there are still many firsts for gravitational-wave astronomy yet to come (hopefully, some to be accompanied by cake). One of the most sought after, is the first is signal to have a clear electromagnetic counterpart—a glow in some part of the spectrum of light (from radio to gamma-rays) that we can observe with telescopes.
Identifying a counterpart is challenging, as it is difficult to accurately localise a gravitational-wave source. electromagnetic observers must cover a large area of sky before any counterparts fade. Then, if something is found, it can be hard to determine if that is from the same source as the gravitational waves, or some thing else…
To help the search, it helps to have as much information as possible about the source. Especially useful is the distance to the source. This can help you plan where to look. For nearby sources, you can cross-reference with galaxy catalogues, and perhaps pick out the biggest galaxies as the most likely locations for the source [bonus note]. Distance can also help plan your observations: you might want to start with regions of the sky where the source would be closer and so easiest to spot, or you may want to prioritise points where it is further and so you’d need to observe longer to detect it (I’m not sure there’s a best strategy, it depends on the telescope and the amount of observing time available). In this paper we describe a method to provide easy-to-use distance information, which could be supplied to observers to help their search for a counterpart.
Going the distance
This work is the first spin-off from the First 2 Years trilogy of papers, which looked a sky localization and parameter estimation for binary neutron stars in the first two observing runs of the advance-detector era. Binary neutron star coalescences are prime candidates for electromagnetic counterparts as we think there should be a bigger an explosion as they merge. I was heavily involved in the last two papers of the trilogy, but this study was led by Leo Singer: I think I mostly annoyed Leo by being a stickler when it came to writing up the results.

Three-dimensional localization showing the 20%, 50%, and 90% credible levels for a typical two-detector early Advanced LIGO event. The Earth is shown at the centre, marked by 
The idea is to provide a convenient means of sharing a 3D localization for a gravitational wave source. The full probability distribution is rather complicated, but it can be made more manageable if you break it up into pixels on the sky. Since astronomers need to decide where to point their telescopes, breaking up the 3D information along different lines of sight, should be useful for them.
Each pixel covers a small region of the sky, and along each line of sight, the probability distribution for distance 
![\displaystyle p(D|\mathrm{data}) \propto D^2\exp\left[-\frac{(D - \mu)^2}{2\sigma}\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+p%28D%7C%5Cmathrm%7Bdata%7D%29+%5Cpropto+D%5E2%5Cexp%5Cleft%5B-%5Cfrac%7B%28D+-+%5Cmu%29%5E2%7D%7B2%5Csigma%7D%5Cright%5D&bg=ffffff&fg=444444&s=0&c=20201002)
where 


The ansatz doesn’t always fit perfectly, but it performs well on average. Considering the catalogue of binary neutron star signals used in the earlier papers, we find that roughly 50% of the time sources are found within the 50% credible volume, 90% are found in the 90% volume, etc. We looked at a more sophisticated means of constructing the localization volume in a companion paper.
The 3D localization is easy to calculate, and Leo has worked out a cunning way to evaluate the ansatz with BAYESTAR, our rapid sky-localization code, meaning that we can produce it on minute time-scales. This means that observers should have something to work with straight-away, even if we’ll need to wait a while for the full, final results. We hope that this will improve prospects for finding counterparts—some potential examples are sketched out in the penultimate section of the paper.
If you are interested in trying out the 3D information, there is a data release and the supplement contains a handy Python tutorial. We are hoping that the Collaboration will use the format for alerts for LIGO and Virgo’s upcoming observing run (O2).
arXiv: 1603.07333 [astro-ph.HE]; 1605.04242 [astro-ph.IM]
Journal: Astrophysical Journal Letters; 829(1):L15(7); 2016; Astrophysical Journal Supplement Series; 226(1):10(8); 2016
Data release: Going the distance
Favourite crisp flavour: Salt & vinegar
Favourite jacaranda: Jacaranda mimosifolia
Bonus notes
Catalogue shopping
The Event’s source has a luminosity distance of around 250–570 Mpc. This is sufficiently distant that galaxy catalogues are incomplete and not much use when it comes to searching. GW151226 and LVT151012 have similar problems, being at around the same distance or even further.
The gravitational-wave likelihood
For the professionals interested in understanding more about the shape of the likelihood, I’d recommend Cutler & Flanagan (1994). This is a fantastic paper which contains many clever things [bonus bonus note]. This work is really the foundation of gravitational-wave parameter estimation. From it, you can see how the likelihood can be approximated as a Gaussian. The uncertainty can then be evaluated using Fisher matrices. Many studies have been done using Fisher matrices, but it important to check that this is a valid approximation, as nicely explained in Vallisneri (2008). I ran into a case when it didn’t during my PhD.
Mergin’
As a reminder that smart people make mistakes, Cutler & Flanagan have a typo in the title of arXiv posting of their paper. This is probably the most important thing to take away from this paper.

 . Figure 5 from
. Figure 5 from  , the mass ratio
, the mass ratio 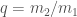 and the total mass
and the total mass 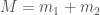 , where
, where  and
and 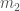 are the masses of the primary and secondary neutron stars respectively. The uncertainties are small for louder signals (higher signal-to-noise ratio). If we neglect the spin, the true chirp mass can lie outside the posterior distribution, the average is about 5 standard deviations from the mean, but if we include spin, the offset is just 0.7 from the mean (there’s still some offset as we’re allowing for spins all the way up to 1).
are the masses of the primary and secondary neutron stars respectively. The uncertainties are small for louder signals (higher signal-to-noise ratio). If we neglect the spin, the true chirp mass can lie outside the posterior distribution, the average is about 5 standard deviations from the mean, but if we include spin, the offset is just 0.7 from the mean (there’s still some offset as we’re allowing for spins all the way up to 1).


 and spin
and spin  of the final black hole. We could use other sets of parameters, but this pair compactly sum up the
of the final black hole. We could use other sets of parameters, but this pair compactly sum up the 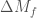 and
and 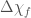 , if general relativity is a good match to the observations, then we expect everything to match up, and
, if general relativity is a good match to the observations, then we expect everything to match up, and 
 , indicated by the cross (+). The left panels show a general relativity simulation, and the right panel shows a waveform from a modified theory of gravity. Figure 1 of
, indicated by the cross (+). The left panels show a general relativity simulation, and the right panel shows a waveform from a modified theory of gravity. Figure 1 of  rather than
rather than 

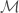 (a much beloved combination of the two component masses which we are usually able to pin down precisely) and the total mass
(a much beloved combination of the two component masses which we are usually able to pin down precisely) and the total mass 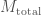 .
.
 is the mass of the stellar-mass black hole divided by the mass of the intermediate-mass black hole. Figure 1 of
is the mass of the stellar-mass black hole divided by the mass of the intermediate-mass black hole. Figure 1 of 

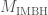 ). Figure 7 of
). Figure 7 of 

 , where
, where 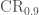 is the 90% sky area and
is the 90% sky area and 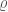 is the signal-to-noise ratio. The results for BAYESTAR and LALInference agree, as do the results with Gaussian and recoloured noise. This is Figure 9 of Berry et al. (
is the signal-to-noise ratio. The results for BAYESTAR and LALInference agree, as do the results with Gaussian and recoloured noise. This is Figure 9 of Berry et al. (
 .
.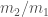 . We can get this from less dominant parts of the waveform, but it’s not typically measured as precisely as the chirp mass, so we’re often left with big uncertainties.
. We can get this from less dominant parts of the waveform, but it’s not typically measured as precisely as the chirp mass, so we’re often left with big uncertainties.

 that is really convenient if you’re a cosmologist, but a pain for anyone else. It does have the advantage of making the pulsar timing arrays look more sensitive though.
that is really convenient if you’re a cosmologist, but a pain for anyone else. It does have the advantage of making the pulsar timing arrays look more sensitive though.

{kind=link}